![]()
![]()
![]() Chapitre 12
Chapitre 12
Le modele de reference OSI
LA COUCHE PRESENTATION : NIVEAU 6
12. 1. Introduction
Pour comprendre le rôle fondamental de la couche présentation (6ème couche dans le modèle OSI de l'ISO) il suffit de considérer les problèmes qui se posent chaque fois qu'un nouveau type de terminal doit être connecté à un ordinateur. Si le modèle de ce terminal n'a pas été prévu par le concepteur du logiciel de l'ordinateur, il va être nécessaire de réaliser des modules d’adaptation propre à ce terminal pour rendre possible une communication. Or, actuellement la plupart des liaisons terminal-ordinateur ont lieu via des réseaux de télécommunication. C’est de la réunion de ces deux faits qui est née la notion de terminal virtuel. Le terminal virtuel est un concept de terminal qui se veut le plus universel possible. Ainsi un ordinateur n'aura plus qu'à prévoir des communications qu’avec ce type unique de terminal; les adaptations aux modèles physiques étant faites par le service de présentation de l'architecture des protocoles ISO. La figure 12.1 schématise l'amélioration apportée par ce concept. Mais le rôle du service de présentation est plus vaste que ce simple terminal virtuel. On peut en effet remarquer que des problèmes similaires se posent lorsqu'il s'agit d'échanger entre machines hétérogènes des informations stockées dans des fichiers. Le service de présentation a également pour rôle de faciliter les manipulations de fichiers entre machines différentes : c'est le concept de fichier virtuel. Le troisième domaine important d'action du service de présentation est de permettre la soumission de travaux à distance sur une machine dont on ne connaît pas à priori le langage de commande. Le service offert dans ce cas est la mise à disposition d'un langage commun à un ensemble de machines hétérogènes reliées par un même réseau.
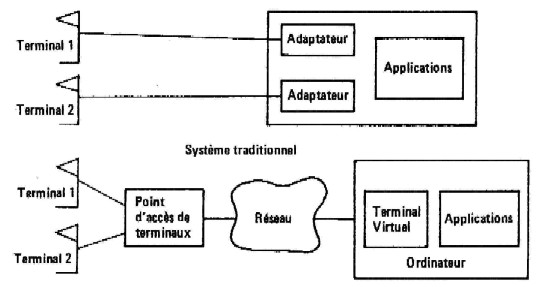
Figure 12.1. : Un exemple de terminal virtuel
Ces trois points principaux ont pour but de permettre l'accès à des machines d'une façon indépendante (ou la plus indépendante possible) de son système d'exploitation. Se posent alors des problèmes d'identification des utilisateurs, d'authentification des transactions et plus généralement de sécurité dans les liaisons. C'est le quatrième volet de l’activité du service de présentation. Enfin, le rôle du service de présentation pourra s'étendre jusqu’à des actions du type compression des données en vue de l'optimisation des temps de transfert des informations volumineuses. La suite de ce chapitre va présenter successivement chacun, des aspects évoqués ci-dessus qui aboutiront à une définition complète de ce qu’est le service de présentation.
12. 2. Le terminal virtuel
La démarche normative pour cette classe de protocole n'est pas encore définitivement arrêtée : aussi nous allons montrer quelques-unes des contributions essentielles qui donneront naissance à la norme dans un futur peu éloigné. La notion de terminal virtuel se matérialise dans la pratique par la mise à jour combinée et simultanée de deux structures de données (une à chaque extrémité de la communication) qui représentent les fonctions essentielles du terminal. La figure 12.2. montre un exemple simple codé en Pascal, de ce que pourrait être une structure de données matérialisant un terminal virtuel simple. Le terminal y est représenté par une structure définissant un écran comme un ensemble de champs de caractères. Il existe également d'autres informations caractérisant la position du curseur dans ces champs, le type réel de terminal connecté, le type de la liaison (simultanée ou à l'alternat) et l'état du terminal sur lequel nous reviendrons ci-dessous. Cette structure de données va être dupliquée aux deux extrémités de la communication et être manipulée par chaque entité de présentation.
type CHAMP = record
TEXTE: array [0.. Maxtexte] of char;
POSX: 0.. maxX;
POSY: 0.. maxY;
JUSTIF: (droite, gauche, entre)
end;
var TERMINAL = record
ECRAN: array [0.. Maxecran] of CHAMP;
CURSEUR: record
x: 0.. Maxtexte;
y: 0.. Maxecran
end;
TYPTERM: (ASR33, VTR2, ZIP);
LIAISON: (Full, Half);
PAROLE: (Lui, Moi);
ETAT: (Normal, Noninit);
end;
Fig. 12. 2. Exemple d'une structure de données représentant un terminal virtuel.
La figure 12.3 illustre ce fonctionnement en parallèle des deux services de présentation. Dans cette figure, on peut signaler que l'entité de présentation du côté terminal remplit un rôle qui est celui du PAD dans un réseau X25. Lors de l'établissement d’une connexion de présentation, une négociation a lieu entre les partenaires. Cette négociation a pour but de préciser les limites acceptables du modèle général manipulé. Dans notre exemple, il s’agit de choisir le type de terminal, le type de liaison et les constantes (au sens Pascal du terme) qui interviennent dans notre définition. L'ETAT du terminal virtuel deviendra donc «Normal» lorsque cette négociation sera terminée et il quittera ainsi l'état «Noninit». Ce concept de structure de donnée permet à chaque extrémité de conserver une image fiable du terminal en cours d’utilisation. Cependant ce concept seul n'est pas suffisant pour un fonctionnement optimal. Aussi les travaux de normalisation en cours prévoient en plus de cette structure de données (qui est statique) la présence d’éléments dynamiques que l'on peut assimiler à des programmes. Ces programmes contiendront des consignes d'exploitation locale des terminaux connectés. Par exemple, on pourrait concevoir un programme de saisie contrôlée des différents champs d'un écran. Ceci est très utile dans un contexte réseau puisqu'à ce moment un échange de données n’aura lieu que lorsque toutes les informations seront correctement connues.
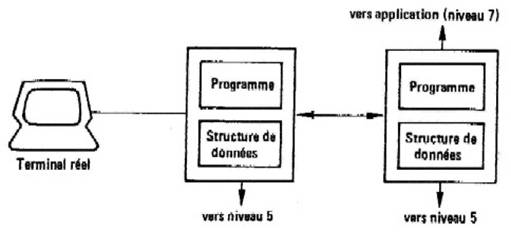
Figure 12. 3. : Fonctionnement du terminal virtuel.
12. 2. 1. La terminal virtuel ARCHITEL
Le groupe français ARCHITEL est l'auteur d'un projet de norme de présentation par un terminal virtuel de type vidéotex. La structure de données de ce terminal virtuel est comparable sur le principe à la figure 12. 2. Plus précisément un terminal virtuel vidéotex se compose de l'ensemble des structures suivantes : document curseur, mémoire de travail, programme de saisie, tables. Le document est la structure de base qui correspond à la fonction principale du terminal qui est de présenter des documents, formulaires, grilles de saisie sur un écran (ou du papier, dans le cas de terminaux de ce type). Le curseur permet de désigner à chaque instant une donnée élémentaire du document (un champ de caractères, par exemple, dans la figure 12.2). La mémoire de travail et le programme de saisie sont liés aux descriptions des traitements locaux à effectuer. Un programme de saisie est une sorte l’automate réagissant à l'aide de règles du type : événement + condition ® action.
Un exemple d’événement peut être la frappe d’une touche particulière (suite, envoi, retour... sur un terminal minitel) ou la fin de saisie d'un champ, ou encore la saisie d’un caractère erroné. Un exemple de condition peut être le curseur en début de document ou en fin de zone de saisie. Enfin, les actions peuvent être, par exemple, l'envoi des données vers le serveur distant, la fin d'une connexion ou encore un accès à la mémoire de travail. Enfin, les tables sont en fait des définitions des différents jeux de caractères qui seront utilisés dans la transmission.
Outre ces définitions de structures de données, le terminal virtuel contient également des valeurs par défaut de chacune de ces structures que le projet ARCHITEL appelle modèle de document modèle de curseur, etc..
Ces modèles permettent ainsi de spécifier complètement ce qui doit être visualisé même dans des phases initiales de la connexion. La figure 12.4 donne une définition plus complète du terminal virtuel vidéotex proposé par ARCHITEL.
Modèle de terminal virtuel
Terminal virtuel
Modèle de document
Document
Modèle de page
Page
Modèle de pavé
Pavé
Modèle de graphisme
Graphisme
Modèle de curseur
Curseur
Modèle de mémoire de travail
Mémoire de travail
Modèle de programme de saisie
Programme de saisie
Modèle de sous-programme de saisie
Sous-programme de saisie
Figure 12.4 : Structure des données du terminal virtuel Vidéotex.
On appelle quelquefois. un profil, le modèle de terminal virtuel. Ce profil définit donc les valeurs par défaut qui caractérisent un terminal particulier. On remarquera également que certaines des structures déjà évoquées se décomposent en entités plus fines. Ainsi un document se compose de pages, qui elles mêmes se composent de pavés, etc. ...
Ces structures seront exploitées par l'entité de présentation qui aura en charge de créer, selon les besoins des applications, des données conformes à ses structures. Ainsi lorsqu'un terminal entre en activité, se trouve créée une donnée de type terminal virtuel avec pour valeur initiale celle définie par le profil. Par suite, chaque fois qu’une donnée nouvelle est créée, chacune des données englobées est créée avec sa valeur par défaut (en référence à son modèle).
Par exemple, lorsqu'une nouvelle page est créée, autant de pavés qu'il en est prévu dans le modèle de page, sont créés immédiatement. Par la suite, il est bien sûr possible de modifier les valeurs initiales de chaque structure pour, par exemple, ajouter un nouveau pavé dans une page préexistante.
En terme de protocole, les messages échangés entre entités de présentation permettent la manipulation explicite de chacune de ces données. En particulier, il existe une famille de messages de type CREATION-X (où X peut être document, pavé, curseur, etc..) qui permet de créer une donnée conforme à un modèle. Cette donnée pourra, elle, être modifiée par une série de messages de type MODIFICATION-X. Chacun de ces types de message possède des paramètres précisant son action exacte. Nous ne détaillerons pas plus ce protocole dans la mesure où ce n’est pas encore une norme officielle et que donc, il est soumis à d'éventuelles modifications.
12. 2. 2. Le modèle NAPLPS
NAPLPS signifie «North American Presentation Level Protocol Syntax». Il est né vers 1982 à partir d’un système de vidéotex développé en 1981 par la société américaine AT&T qui s'appelait PLP (Presentation Level Protocol). Ce système (NAPLPS) a également quelques racines dans le système Telidon (vidéotex canadien) ainsi que dans la norme Antiope (vidéotex français). Dans la mesure où ce système est une proposition de standard de présentation au niveau mondial, il est intéressant de le présenter ici.
NAPLPS a été conçu au départ pour acheminer sur des lignes de communication à basse vitesse (lignes téléphoniques, par exemple), des informations au caractère graphique important Le système d'encodage des informations utilisé par NAPLPS est compatible avec le code ASCII (code CCITT n°5 en Europe) et permet ainsi sa mise en oeuvre simple.
Dans ce standard, les images sont décrites dans un système de coordonnées virtuelles à l'aide d'instructions de définition d'image. Par souci de compatibilité avec un plus grand nombre de. systèmes existants, NAPLPS permet également la gestion de jeux de caractères «mosaïques» à la manière du vidéotex français.
Le principe de base de ce système est de représenter les informations graphiques sous forme de points, de lignes, d’arcs ou de polygones dans un système de coordonnées cartésiennes. Une image pour NAPLPS est un rectangle dont les coordonnées du coin inférieur gauche sont (0, 0) et celles du coin supérieur droit sont (1, 1). L'avantage d’un tel système est l'indépendance totale ainsi créée vis-à-vis des matériels existants pour ce qui concerne la description d’un document. C’est de la responsabilité de chaque implémentation que de réaliser une correspondance entre ce format de document et la définition réelle de son image. Cet avantage pose néanmoins quelques problèmes, le premier est qu’un écran de télévision ordinaire n'est pas un carré parfait de sorte qu’un ne peut représenter qu’à peu près 3/4 d'une image virtuelle NAPLPS; le deuxième problème est dans le choix des algorithmes de correspondance entre l'image NAPLPS et les points d’un écran informatique (comment «dégrader» une image haute définition sur un terminal à faible résolution par exemple).
Il est également possible dans ce système de créer des «macrocommandes» réalisant une fonction particulière : dessin du sigle d'une société par exemple (cette possibilité est à rapprocher de la définition de la mémoire de travail dans le service de présentation ARCHITEL).
Un exemple de spécification d'un dessin simple est montré à la figure 12. 5. Dans cet exemple, chaque commande est codée (en pratique) par un octet suivi des informations de déplacement q’il nécessite. Les nombres évoqués dans ces commandes sont des coordonnées absolues lorsqu'ils ne sont pas signés, et des informations relatives lorsqu’un signe est présent.
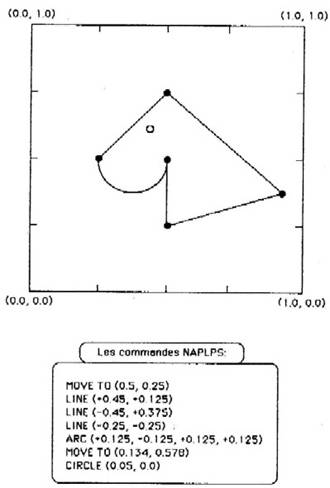
Figure : 12.5. : Un exemple de dessin par NAPLPS.
Nous avons indiqué précédemment que NAPLPS était compatible avec le codage ASCII des caractères. Voyons plus en détail comment cela fonctionne : Il a été décidé de représenter toutes les informations (caractères comme commandes purement graphiques) dans une table de 256 valeurs (soit un codage sur un octet). Cette table est organisée en 16 lignes de 16 colonnes et divisée en quatre zones (figure 12.6).
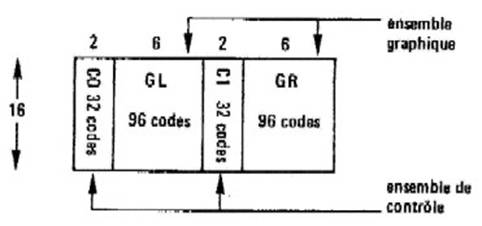
Figure 12.6 : L a table de codage NAPLPS.
A l'intérieur de ces zones peuvent être chargés ou enlevés différents jeux de caractères ou de commandes. On réalise ainsi ce qu’on appelle une extension de code et cette méthode est conforme à la recommandation ISO 2022.2. A un instant donné, seuls 256 codes (avec leur signification propre) sont reconnus et interprétés. Il est possible de choisir les jeux présents dans GL (Graphic Left) et GR (Graphic Right) parmi, actuellement 6 jeux disponibles, qui sont :
- le jeu primaire (qui est en fait le code ASCII)
- le jeu complémentaire (qui regroupe des caractères utiles dans les langues étrangères et quelques graphiques); c'est le jeu G2 du vidéotex français
- le jeu de description d'image (PDI : Picture Description Instructions dans lequel on trouve les commandes de la figure 13.5)
- le jeu mosaïque (qui est le jeu semi-graphique G1 du vidéotex français)
- le jeu de caractères dynamiquement redéfinissables (DRCS, Dynamically Redefinable Character Set) qui permet aux utilisateurs de créer leur propre jeu de caractères
- le jeu « macro » qui permet de désigner des traitements complexes préenregistrés, à l'aide d'un seul caractère.
La figure 12.7 montre les quatre premiers de ces jeux (les autres étant initialement vides et à remplir par l'utilisateur). Le même mécanisme est prévu pour les jeux C0 et C1 (figure 12.6) mais à l'heure actuelle ces jeux de contrôle sont figés. C’est à l'aide de ces jeux de contrôle (que l'on peut voir Figure 12. 8) que sont gérés les échanges des jeux G. On trouve également dans C1 les commandes pour créer un jeu DRCS ainsi que des macros.
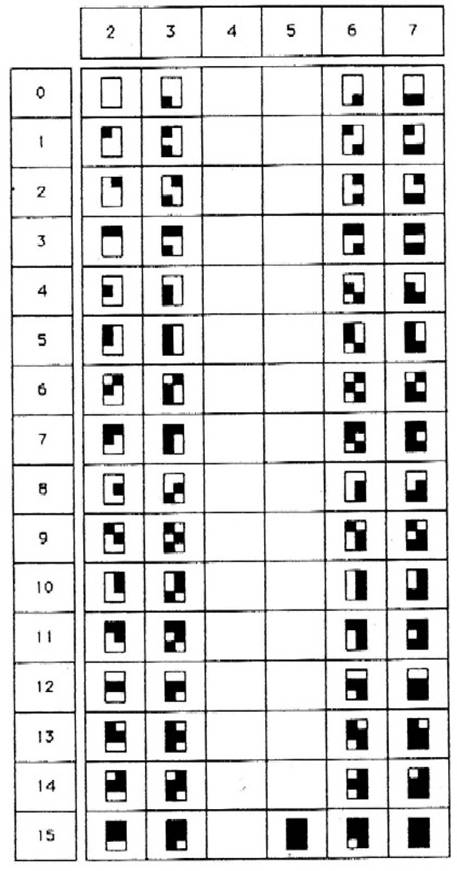
Figure 12.7.a : Les jeux graphiques NAPLPS.
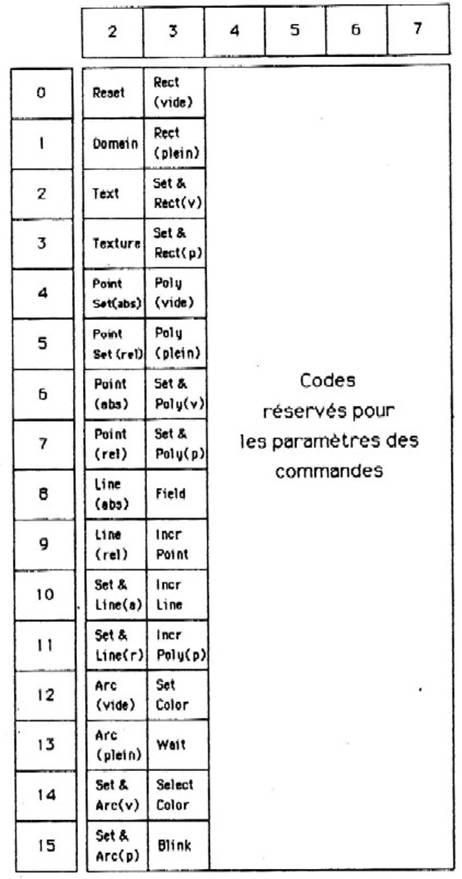
Figure 12.7.b : Les jeux graphiques NAPLPS.
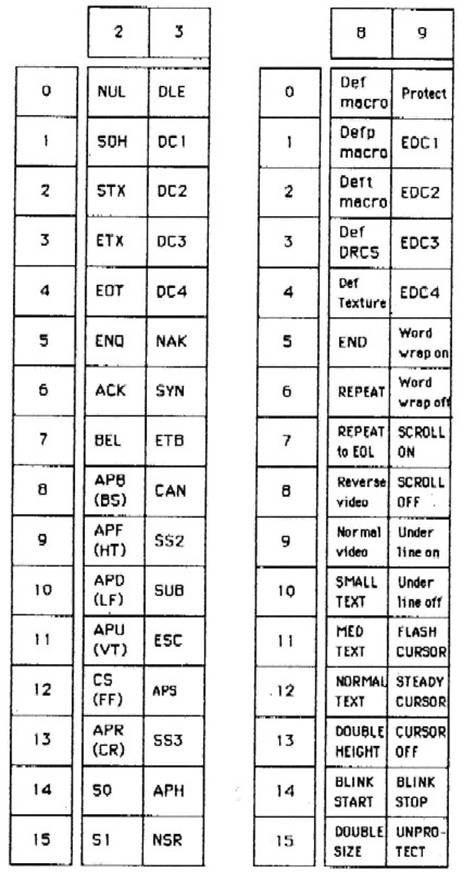
Figure 12.8 : Les jeux de contrôle NAPLPS.
Nous n'entrerons pas plus dans le détail de ce standard qui connaît actuellement de très importants développements dans le domaine de l'échange de données (textuelles ou graphiques) entre micro-ordinateurs. Il est intéressant de noter que les deux contributions à la norme du niveau présentation de l'ISO que nous venons de voir tirent leur «histoire» des applications en cours du vidéotex. Il est très probable qu'une unification de ces propositions interviendra lors de la publication définitive de la norme.
12. 2. 3. Conclusion sur les terminaux virtuels
Beaucoup d’approches différentes du problème de la présentation des données aux terminaux ont été réalisées dans le cadre de nombreux projets. Historiquement c'est certainement le réseau ARPANET qui a proposé les premières solutions avec son protocole TELNET. En France, le projet CYCLADES, prélude au réseau TRANSPAC a fortement contribué à la création des normes X3, X28 et X29 du CCITT qui créent un contexte de terminal virtuel à l'aide des PADs.
12. 3. Le fichier virtuel
La façon dont sont organisés les systèmes de gestion de fichiers sur des machines différentes est tellement variable qu'il est souvent difficile, voir impossible, de traiter à distance des données structurées. C'est cette idée qui a conduit à construire un modèle de description des fichiers et de leurs attributs pouvant ensuite permettre la définition de services et de protocoles pour le transfert d'information, l'accès à des données ou l'organisation des fichiers. C'est cet ensemble qu'on appelle système de fichier virtuel. Comme dans le cas du terminal virtuel. le rôle de la couche présentation du modèle OSI sera de réaliser la traduction (l'adaptation) entre les structures réelles de chaque machine et cette structure virtuelle uniforme.
La normalisation de cette structure de fichier virtuel n'est pas encore arrêtée par les instances internationales, aussi des indications que nous donnons ciaprès font référence aux contributions les plus importantes à la norme future (et non pas à cette nonne elle-même).
Dans cet esprit on peut définir le fichier virtuel comme étant une entité qui possède :
· un nom permettant de l'identifier sans ambiguïté,
· des attributs descriptifs tels que taille, informations comptables, histoire...,
· des attributs définissant la structure logique et la dimension des données stockées,
· enfin, les données elles-mêmes.
Les services et les protocoles qui découlent de la nécessité de créer un environnement cohérent au dialogue de manipulation de ces fichiers, vont s'articuler autour de 4 phases principales qui sont :
- reconnaissance des interlocuteurs (identités et droits mutuels)
- reconnaissance du fichier à traiter
- reconnaissance de la structure des informations à manipuler
- mise en oeuvre des traitements proprement dits.
La première phase n'est pas spécifique du traitement des fichiers virtuels. Elle Rapplique en général à toute application distribuée entre deux sites. Au contraire, la deuxième phase établit ridentité du fichier que l'on va traiter en le désignant par son nom ou par d’autres attributs le caractérisant précisément. La troisième phase correspond à couverture du fichier dans un système traditionnel de gestion. Quant à la quatrième phase, d'est la mise en oeuvre des traitements spécifiées.
12. 3. 1. Les attributs d'un fichier
Nous allons donner ici une liste d’attributs (avec leur définition) permettant de caractériser un fichier et ses possibles traitements en référence du projet de normalisation actuel. Le premier attribut est bien sûr un nom defichier. Ce nom doit être unique pour permettre une désignation non ambiguë des informations. La structure des noms définitivement adoptée sera certainement une structure hiérarchique permettant plus facilement le repérage dans une machine spécifique des informations. Il est également prévu de limiter à 64 caractères la longueur du nom d’un fichier.
Le type d'accès possible sur le fichier constitue le deuxième attribut d'un fichier. Il faut choisir parmi deux organisations des données : séquentielle ou aléatoire en excluant forganisation séquentielle indexée. Pourtani très utilisée, cette dernière ne possède pas suffisamment de caractères communs d'une machine à l'autre pour être partie intégrante d'un modèle général. L'organisation étant choisie, il faut définir les accès possibles parmi lecture seule, écriture seule ou lecture-écriture. Il est prévu de fixer cet attribut à la création du fichier et de ne pas pouvoir la changer ultérieurement.
Le contrôle d'accès est une liste de conditions dont au moins une doit être satisfaite pour permettre l'accès à f information. Ces contrôles d'accès permettent de définir les opérations réalisables pour un utilisateur (ou un groupe d'utilisateurs) désigné par un nom et éventuellement un mot de passe (la taille prévue de ce mot de passe est de 32 octets). La différence entre cet attribut et le précédent est la restriction que l'on peut ici apporter à certaines classes d'utilisateurs par rapport aux possibilités réelles de traitement spécifiées par l'attribut précédent.
Un attribut de comptabilisation est également présent pour désigner le responsable (financier) des traitements effectués sur les informations du fichier indépendamment des méthodes de calcul des coûts ainsi évoqués.
Des informations sur l'histoire du fichier sont présentes ici. Il s'agit des dates et heures de création, de dernière modification et de dernière lecture. On trouve aussi Fidentité du créateur du fichier sous forme d'une suite de 16 octets au plus. De même sont enregistrées les identités des acteurs ayant provoqué la dernière modification et la dernière lecture.
Il est prévu d’autres attributs permettant de classifier des fichiers à accès immédiatement disponible ou à accès différé, le type des caractères utilisés (les alphabets de codage par exemple), les méthodes de cryptage utilisées, etc..
Enfin la taille du fichier actuel ainsi que celle qu'il peut être amené à prendre par suite d'adjonction d’infonnation. Cette deuxième information est surtout indicative pour le système de gestion réel du fichier. En tout état de cause, cette taille sera exprimée en octets. Ces attributs présentent les caractéristiques du fichier proprement dit pas du traitement qüon peut être amené à lui faire subir. Ces traitements possèdent également leurs propres descripteurs que nous allons présenter maintenant.
12. 3. 2. Les attributs des traitements
Ces attributs vont caractériser l'état de l'accès au fichier en cours et donc, le premier sera le type d'accès demandé qui sera à choisir parmi :
· lecture
· insertion
· remplacement
· destruction
· extension
· lecture des attributs
· modification des attributs
· destruction du fichier
En plus de ces actions optionnelles, un nombre d'actions obligatoires sur tout fichier peuvent être entreprises. Il s'agit de :
· sélection d'un fichier
· ouverture d’un fichier
· fermeture d'un fichier
· localisation d'une donnée
· désélection d’un fichier
Une caractéristique de la connexion est l'identité du demandeur qui sert d'authentification pour la demande de traitement. En complément de cette information, on trouve un mot de passe, une adresse du demandeur et un compte sur lequel seront imputées les dépenses liées aux traitements entrepris. Enfin il est prévu d'indiquer si oui ou non un accès parallèle au fichier sera possible pour permettre un éventuel accès exclusif (ou au contraire un accès partagé) à l'information.
12. 3. 3. Le service du fichier virtuel
Le service de fichier virtuel offert sur une connexion offre un caractère intrinsèque ifasymétrie. En effet le type de traitements engagés est souvent demandé par un site où ne se trouve pas le fichier, de sorte que l'initiateur des demandes est rarement celui qui « possède réellement » l'information. Aussi les primitives du service de fichier virtuel possèdent-elles ce caractère asymétrique en ce sens que certaines ne peuvent être émises que par l'initiateur d'une connexior4 alors que d'autres peuvent être émises par les deux participants. La figure 13.9 montre le nom des différentes primitives disponibles ainsi que le type de réponse quelles demandent en cas de suczès (confirmation en cas d'échec).
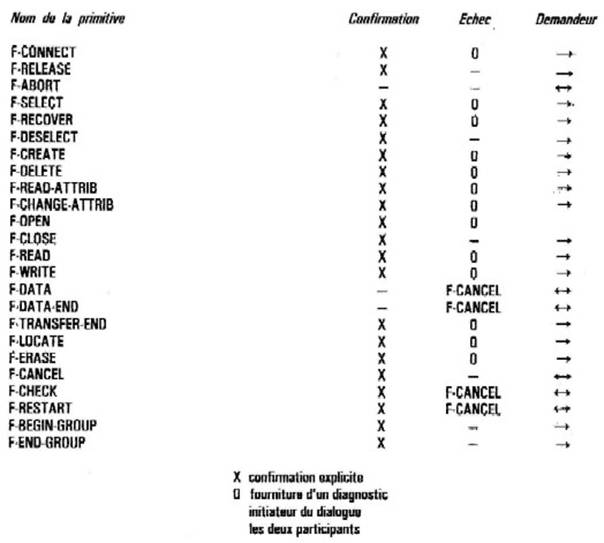
Figure. 12.9: Les primitives du service fichier virtuel.
L'enchaînement de ces primitives donne lieu au diagramme d’état simplifié de la figure 12.10 qui rend compte de l'activité d'un serveur de fichier virtuel du point de vue de la communication. Traduit en terme d'échanges de messages, ce diagramme peut donner lieu à un comportement comme indiqué à la figure 12. 11. pour une opération Réecriture dans un fichier distant. Nous avons supposé dans cet exemple l'absence d'erreur dans le déroulement des opérations. Lorsqu'une erreur a lieu, un compte rendu (voir fig. 12.9) est envoyé qui explicite la raison de l'échec et son caractère de gravité succès, 1 = attention, 2 = erreur récupérable, 3 = erreur irrécupérable.
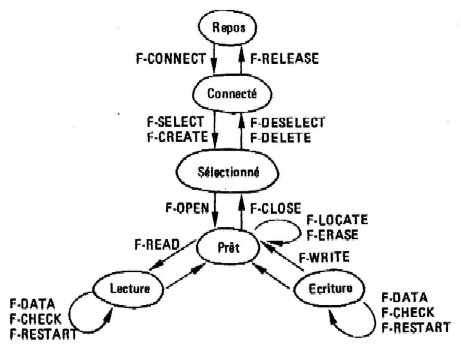
Figure 12.10. Diagramme d'état d'un serveur fichier virtuel.
12. 3. 4. Conclusion sur le fichier virtuel
Les indications données ici sur la notion de fichier virtuel normalisé nous amènent à nous demander s'il peut n'exister qu'un seul type de fichier virtuel adaptable à toute situation. Cependant ce qui est ici présenté est l'état de la démarche actuelle de normalisation en ce domaine. Une spécification du protocole permettant la réalisation de ces services est disponible auprès de l'ISO.
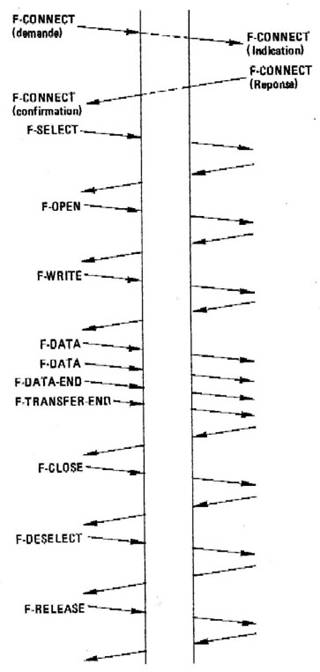
Figure 12.11 : Un exemple d'écriture dans un fichier (pas d'erreurs)
12. 4. Soumisson de travaux à distance
Lorsque l'on aborde le problème de la soumission des travaux à distance, on pense souvent au traitement par lots. Cette association semble donner à ce problème peu d'importance pour des raisons historiques (diminution du traitement par lots au profit des applications transactionnelles). Cependant il est toujours nécessaire de spécifier à une machine distante des travaux à effectuer si ceux-ci sont longs et impossibles à traiter localement. Il existe deux types principaux de systèmes d'entrée de travaux à distance (RJE : Remote Job Entry, en anglais) qui sont basés sur deux approches différentes :
· création ifun langage de commande du réseau indépendamment des machines (et de leurs systèmes d’exploitation) qui y sont connectées;
· création d’un terminal lourd virtuel qui fonctionnera selon le même principe que le terminal virtuel sinple évoqué plus haut dans ce chapitre. Ce terminal lourd virtuel disposera d'impr23-Jul-2008
La plupart des systèmes existants sont basés sur le principe de la deuxième famille. L'avantage est que l'utilisateur dispose toujours de toutes les fonctionnalités disponibles sur la machine cible à raide de son langage de commande propre. Dans le premier cas, pour s'adapter aux potentialités de tous les langages de commande, le langage réseau se trouve être un noyau minimum des commandes disponibles (ou exécutables) sur chaque machine connectée. L'avantage de cette solution est d’offrir à rutilisàteur un ensemble de serveurs partiels dont il n'a pas toujours besoin de connaître l'identité réelle. Les principales fonctionnalités attendues d’un système ifentrée de travaux à distance sont donc (pour'le deuiième type de système) :
· soumission de travaux et ifidentification de l'utilisateur
· recherche, consultation et édition des résultats
· modification d'un travail en cours (priorité...)
· contrôle du transfert des travaux dans le réseau.
12. 5. Cryptage, authentification et compression des données
Le titre de ce paragraphe regroupe des fonctions diverses sans lien de parenté immédiat. La raison en est que ces techniques ont déjà été définies dans leur principe lors d’autres chapitres. Il est cependent important de signaler que leur domaine d'application est également le niveau de présentation des données où leur rôle peut s'avérer indispensable. En particulier, il peut être nécessaire de crypter des informations au niveau présentation lorsque le fournisseur du service de transport organisme différent de celui qui effectue des transferts d’informations confidentielles (cf. le problème des banques...)
12. 6. Conclusion
Ce chapitre a essayé de passer en revue les principales composantes de la couche présentation de l'ISO. A l'heure actuelle où les démarches de normalisation ne sont pas encore arrêtées dans ce domaine, peu d'unité se fait jour entre ces différentes parties. Plusieurs obstacles se dressent sur le chemin d'une unification cohérente parmi lesquels on peut citer l'influence des grands constructeurs d'ordinateurs dont cette couche (présentation) entre de plein fouet dans le domaine du développement des logiciels de système d'exploitation. Une norme finale ne pourra paraître et être appliquée que si les constructeurs rappuient complètement. Ceci nous place devant un problème dont la solution ne pourra intervenir dans les faits avant plusieurs années en raison particulièrement du suivi des applications actuelles des clients de ces constructeurs parrimpossibilité d’appliquer rapidement des modifications brutales aux logiciels de base.
![]()
![]()
![]()