![]()
![]()
![]() Chapitre 5
Chapitre 5
Gestion des fichiers
V-1. Allocation des ressources
Nous avons évoqué tout au long des chapitres II et III le fonctionnement des processus. Nous avons décrit les problèmes que posait le partage des ressources (section 2.2.2) dans le cas de processus coopérants. La réalité des systèmes multi-tâches et temps partagé est plus complexe : le système d'exploitation doit distribuer ces ressources de la façon la plus harmonieuse entre processus indépendants. Celles-ci sont rares, les processus qui les réclament sont nombreux et ils sont en compétition pour en obtenir l'usage. Les stratégies adoptées pour résoudre ce problème feront l'objet du présent chapitre.
Nous évoquerons les méthodes de partage des périphériques, de la mémoire ou du processeur. Celles-ci doivent être le plus efficace possible pour assurer un fonctionnement harmonieux sans blocage ni surcharge. L'efficacité d'un ordinateur est directement liée aux solutions mises en oeuvre pour résoudre ces problèmes. Comme nous le verrons il n'existe pas une méthode optimale unique mais des solutions pour chaque problème et des différences de performances étonnantes peuvent exister suivant le choix retenu: par exemple le même ordinateur se révèle 3 à 5 fois plus rapide pour calculer une transformée de Fourier lorsqu'il fonctionne sous Unix et non sous Windows! Ceci est lié à la gestion de la mémoire qui est peu performante. Cela n'est pas aussi caricatural pour d'autres situations.
On désigne sous le nom de ressource tout objet utilisé par un processus. Les fichiers sont donc un exemple particulier de ressource mais on emploie plutôt ce vocable lorsqu'on s'intéresse au problème de leur allocation ou de leur partage ainsi qu'aux moyens nécessaires pour réaliser ces actions. Une ressource doit d'abord être allouée à un processus avant que celui-ci puisse l'utiliser grâce à ses procédures d'accès. Après usage elle est libérée ou désallouée. Si ce retrait est forcé on dit que la ressource est réquisitionnée au profit d'un autre processus. Une ressource est banalisée lorsqu'il en existe plusieurs exemplaires qui peuvent être alloués indifféremment aux processus qui en font la demande.
L'intention des concepteurs de systèmes d'exploitation est de satisfaire les requêtes des différents processus de manière équitable :
| q des processus de même priorité doivent partager également une ressource. |
| q un processus plus prioritaire doit être satisfait en premier mais il faut éviter de bloquer, dans la mesure du possible, le fonctionnement d'un autre moins prioritaire. |
Certains algorithmes d'allocation peuvent se révéler dangereux car ils amènent à la privation de ressources donc à la famine certains processus.
V-2. Partage du temps de calcul: l'exemple du traitement par lot
La notion de batch a peu à voir avec la terminologie employée par DOS qui évoque un enchaînement de commandes inscrites dans un fichier. Sous Unix cela s'appelle un script.
Le traitement par lot ou batch est employé pour calculer lorsqu'un programme ne demande que peu de dialogue avec un opérateur humain. Comme il est inutile de mobiliser un terminal on remplace celui-ci par deux fichiers, l'un utilisé pour entrer les données qui y ont été enregistrées à l'avance, l'autre pour les écritures. Ceci libère l'écran pour un autre usager. Le travail se déroule en arrière plan ou background. Unix OS/2, Windows NT possèdent cette facilité. Le batch se déroule à une priorité réduite par rapport à l'usage interactif de la machine car un être humain est moins sensible à un allongement du délai de restitution d'un travail lorsqu'il peut employer son temps à autre chose que lorsqu'il attend devant son terminal la réponse de l'ordinateur à la requête qu'il vient de frapper sur son clavier.
Une congestion peut se produire lorsqu'on mobilise un terminal pour exécuter un calcul non interactif: un processus exécuté en batch se trouvera bloqué car moins prioritaire et son utilisateur injustement pénalisé. Pour tenter de remédier à ce problème, et de façon plus générale pour éviter que les usagers interactifs n'abusent de leurs privilèges en exécutant dans cet environnement des tâches qui dialoguent fort peu et ne nécessitent donc pas l'usage d'un terminal, on peut imaginer plusieurs améliorations. La première, souvent utilisée dans les systèmes Unix, est de limiter l'usage du processeur: lorsqu'un processus interactif calcule plus qu'un temps limite il est arrêté. Les gros calculs ne peuvent donc être exécutés qu'en traitement par lot.
Une méthode plus subtile est de réduire progressivement la priorité d'un processus interactif lorsqu'il ne fait que calculer (fig. 5.1).
|
|
| figure 5.1 : Exemple de gestion des priorités |
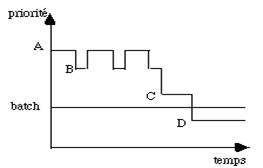
Celle-ci ne redevient normale que lorsqu'une entrée-sortie se produit. On peut même régler le système pour que la priorité tombe en dessous de celle du batch. Le fait de tenter d'exécuter en interactif un travail qui n'en relève pas devient alors franchement pénalisant et cela peut bloquer les abus. Dans le schéma de la figure 5.1 un travail interactif commence avec une priorité A supérieure à celle du batch. Elle est réduite au niveau B s'il calcule trop longtemps mais remonte au niveau A dés qu'il effectue une entrée-sortie. Enfin si les calculs sans dialogue se poursuivent trop longtemps, la priorité décroît au niveau B puis C et enfin D où il se trouve pénalisé puisque le batch est alors plus prioritaire.
Unix ne possède, en natif, que des possibilités rudimentaires de batch. On peut, par la commande at, déclencher le démarrage d'une application à une heure donnée, sans connexion de son utilisateur sur un terminal. Il existe des produits plus élaborés dans le domaine public ou chez des fournisseurs. Les requêtes sont placées dans des files d'attente en fonction de critères propres au centre de traitement : taille mémoire demandée, temps maximum de calcul prévu, quantité d'entrées-sorties... Le responsable du système déclenche les files d'attente soit manuellement soit automatiquement en fonction de la charge. Il est même possible de distribuer les requêtes sur un ensemble de machines connectées en réseau qui partagent leurs disques. En pratique ces possibilités ne sont implantées que dans des centres qui sont amenés à gérer de gros calculs c'est à dire dans le domaine scientifique essentiellement.
V-3. Files d'attente: exemple du partage du processeur
Imaginons que l'on doive partager une ressource banalisée dont le nombre d'exemplaires est insuffisant. Il faut alors associer à chacune de ses réalisations une file d'attente. La réalité est souvent plus compliquée car plusieurs exemplaires d'une même ressource peuvent être liées à un nombre variable de files d'attente. Il faut alors non seulement gérer cet ensemble mais aussi distribuer les demandes dans chaque file pour exploiter au mieux chaque exemplaire de la ressource. Dans les systèmes distribués la difficulté est encore plus grande car il n'existe pas de moyen simple de connaître l'état de toutes les ressources sur toutes les machines du réseau.
Nous nous limiterons ici à l'étude du problème d'une ressource unique servie par une seule file d'attente. Le partage du processeur d'un ordinateur en est un bon exemple.
V-3.1. Files d'attente
Imaginons plusieurs processus qui demandent également à calculer. Lorsque la machine est monoprocesseur ils doivent se partager cette ressource unique. Ces processus, appelés clients, sont mis dans une file d'attente et le service demandé leur est fourni tour à tour, en fonction de critères de gestion spécifiques à la file. Plusieurs situations peuvent se produire (fig. 5.2) :
- la demande d'un processus est entièrement satisfaite. Il n'a plus besoin du processeur. Dans ce cas il quitte la boucle et disparaît.
- la ressource est déjà utilisée par un autre processus. Il attend.
- La ressource est réquisitionnée par un processus plus prioritaire. Le processus actif est remis dans la file d'attente.
Le scheduler gère la file d'attente. Il gère l'arrivée des demandes et les place dans la file. Le dispatcher suit l'activité du processeur, il choisit la requête, en file d'attente, à traiter. Il gère donc l'allocation du processeur. Il peut le réquisitionner en fonction de la priorité des processus demandeurs et du temps déjà consommé par celui qui est en cours d'exécution.
Le temps de réponse d'un système, c'est à dire le temps qui s'écoule entre entrée et sortie de la file d'attente, est fonction de la politique choisie par le dispatcher et de la disponibilité de la ressource.
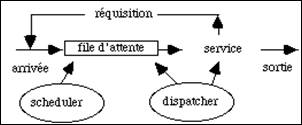
figure 5.2 : Allocation du processeur du batch et de l'interactif
Nous allons évoquer trois politiques possibles :
| q le modèle FIFO (First In First Out) où le dispatcher alloue le processeur au processus arrivé le premier dans la file d'attente. C'est l'exemple de la file d'attente à un arrêt de taxi. |
| q le modèle SJF (Shortest Job First) qui sert de façon prioritaire la requête qui demande le moins de temps au processeur. |
| q le modèle du tourniquet où il existe plusieurs files d'attente. |
V-3.1.1. Le modèle FIFO
Le premier processus entré dans la file d'attente est le premier servi. Dans un modèle aussi simple il est impossible de gérer des processus de priorité différente car la file est unique. Ce modèle est par contre bien adapté au partage du processeur par des processus de même priorité. Il faut alors créer autant de files que de niveaux différents. Nous allons l'étudier dans le cas du temps partagé où tous les processus utilisateurs possèdent la même priorité. Pour simplifier, nous supposerons que la tranche de temps allouée à chaque processus est constante, ce qui est évidemment très simplificateur et ne permet pas de généraliser cette étude à d'autres cas.
Soit ![]() le temps d'attente moyen ou temps de réponse. Ceci est le temps qui sépare l'instant où une demande est faite, après avoir frappé une commande sur le clavier, de celui où l'ordinateur répond à cette requête. Des études ont montré qu'au-delà d'une seconde l'impression psychologique est désastreuse. Appelons
le temps d'attente moyen ou temps de réponse. Ceci est le temps qui sépare l'instant où une demande est faite, après avoir frappé une commande sur le clavier, de celui où l'ordinateur répond à cette requête. Des études ont montré qu'au-delà d'une seconde l'impression psychologique est désastreuse. Appelons ![]() le temps moyen de service alloué à chaque processus, 1/
le temps moyen de service alloué à chaque processus, 1/![]() le temps moyen qui sépare l'arrivée de deux requêtes consécutives, en provenance de deux processus différents, dans la file d'attente. Le temps d'attente
le temps moyen qui sépare l'arrivée de deux requêtes consécutives, en provenance de deux processus différents, dans la file d'attente. Le temps d'attente ![]() augmente lorsque les requêtes se font plus nombreuses et la saturation se traduit par:
augmente lorsque les requêtes se font plus nombreuses et la saturation se traduit par: ![]() .
. ![]() est la charge de l'ordinateur. Ce nombre est sans dimension.
est la charge de l'ordinateur. Ce nombre est sans dimension.
|
|
| figure 5.3 : Evolution de la charge |
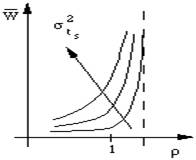
La figure 5.3 montre qualitativement la variation du temps d'attente en fonction de la charge. Lorsque ![]() atteint 1 le temps séparant l'arrivée des requêtes devient égal au temps moyen de service. Le processeur est constamment employé. Si la demande augmente encore la file d'attente s'allonge, la saturation est dépassée et le temps de réponse
atteint 1 le temps séparant l'arrivée des requêtes devient égal au temps moyen de service. Le processeur est constamment employé. Si la demande augmente encore la file d'attente s'allonge, la saturation est dépassée et le temps de réponse ![]() croît alors très rapidement. En réalité les temps de service demandés ne sont pas égaux car certains processus sont interrompus par une demande d'entrées/sorties. On caractérise leur dispersion par l'écart-type
croît alors très rapidement. En réalité les temps de service demandés ne sont pas égaux car certains processus sont interrompus par une demande d'entrées/sorties. On caractérise leur dispersion par l'écart-type ![]() de leur distribution qui est poissonienne. Les différentes courbes représentées dans la figure 5.3 montrent la dégradation du temps de réponse en fonction de cette dispersion.
de leur distribution qui est poissonienne. Les différentes courbes représentées dans la figure 5.3 montrent la dégradation du temps de réponse en fonction de cette dispersion. ![]() augmente avec
augmente avec![]() , ce qui est fâcheux car par nature un usage interactif signifie des demandes de temps de service très dispersées. Ce modèle simple montre déjà combien il est difficile de prévoir la tenue en charge d'un ordinateur car il est extrêmement délicat de simuler la répartition des demandes. On constate que le modèle de file d'attente FIFO a l'inconvénient de ne plus répondre de façon satisfaisante lorsqu'on approche de la saturation. Un ordinateur peut alors donner l'impression d'être bloqué puisque les temps de réponse tendent vers une limite asymptotique infinie.
, ce qui est fâcheux car par nature un usage interactif signifie des demandes de temps de service très dispersées. Ce modèle simple montre déjà combien il est difficile de prévoir la tenue en charge d'un ordinateur car il est extrêmement délicat de simuler la répartition des demandes. On constate que le modèle de file d'attente FIFO a l'inconvénient de ne plus répondre de façon satisfaisante lorsqu'on approche de la saturation. Un ordinateur peut alors donner l'impression d'être bloqué puisque les temps de réponse tendent vers une limite asymptotique infinie.
V-3.1.2. Modèle SJF
Dans le modèle SJF (Shortest Job First) appelé aussi "le plus court d'abord" le scheduler utilise le temps de réquisition de la ressource (ou son estimation) comme critère de priorité. Les demandes les plus courtes sont satisfaites d'abord, donc ce sont les processus qui demandent le moins de temps du processeur qui sont servis les premiers. On remarquera que, à la différence du modèle précédent, on suppose que cette information est connue avant l'exécution. Ce modèle est bien adapté à la description du traitement par lot où l'on doit préciser, lorsqu'on soumet une requête, le temps maximum de calcul. Le travail le moins demandeur est servi le premier.
|
|
| figure 5.4 : Evolution du temps d'attente |
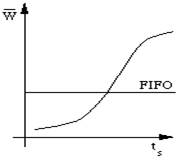
La figure 5.4 montre comment le temps de réponse varie en fonction du temps demandé, à charge constante, c'est à dire pour une valeur fixe de ![]() . Dans ce graphique, un point d'une courbe de la figure 5.3 du modèle FIFO, correspond à une droite horizontale. Plus
. Dans ce graphique, un point d'une courbe de la figure 5.3 du modèle FIFO, correspond à une droite horizontale. Plus ![]() augmente plus cette droite se trouve dans le haut du graphique. La comparaison des courbes montre que la politique SJF est favorable aux travaux les plus courts mais est mauvaise pour les plus longs. De plus, si le temps moyen entre les arrivées des requêtes courtes diminue (c'est à dire si
augmente plus cette droite se trouve dans le haut du graphique. La comparaison des courbes montre que la politique SJF est favorable aux travaux les plus courts mais est mauvaise pour les plus longs. De plus, si le temps moyen entre les arrivées des requêtes courtes diminue (c'est à dire si ![]() augmente), les travaux les plus longs risquent de rester éternellement en file d'attente et ne seront jamais exécutés. Ceci est quasiment la situation que l'on vit dans une file d'attente de téléski aux heures de pointe lorsque les écoles de ski prioritaires se présentent: il n'y a plus aucun espoir de passer. La seule possibilité est alors de forcer la priorité pour pouvoir donner aux processus leur temps de service. C'est le rôle du scheduler
augmente), les travaux les plus longs risquent de rester éternellement en file d'attente et ne seront jamais exécutés. Ceci est quasiment la situation que l'on vit dans une file d'attente de téléski aux heures de pointe lorsque les écoles de ski prioritaires se présentent: il n'y a plus aucun espoir de passer. La seule possibilité est alors de forcer la priorité pour pouvoir donner aux processus leur temps de service. C'est le rôle du scheduler
Le problème est identique pour les systèmes de gestion d'imprimantes sophistiqués. Imprimer les travaux les plus courts peut bloquer, en cas de saturation, les impressions les plus longues. On corrige ce défaut en augmentant régulièrement la priorité des travaux les plus longs, en fonction du temps qu'ils ont déjà passé dans la file d'attente, jusqu'à dépasser celle des plus petits. Dans tous les cas la méthode SJF ne peut être employée que lorsqu'on peut estimer par avance la demande de la ressource.
V-3.1.3. Le modèle du tourniquet
Le modèle du tourniquet ou round robin représente assez bien une politique d'allocation du processeur pour le temps partagé, plus sophistiquée que le premier modèle évoqué.
On alloue au processus, placé en tête de la file d'attente FIFO F0, un quantum de temps Q0. Si ce processus est interrompu par une demande d'entrées-sorties, avant la fin de ce quantum de temps, il est renvoyé dans F0. Le processeur est alors alloué au processus suivant placé en tête de F0. Lorsque le processus n'a pas fini son calcul, à la fin du quantum Q0, le processeur est réquisitionné par le dispatcher qui l'alloue au processus placé maintenant au début de la file d'attente F0. Jusque là le schéma n'est pas différent du modèle FIFO que nous avons déjà décrit dans la figure 5.1.
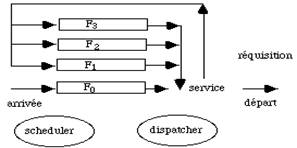
figure 5.5 : Allocation du processeur dans le modèle du tourniquet
En réalité le système de gestion possède N files d'attente. A son arrivée le processus a été rangé dans la file la plus prioritaire F0. Lorsqu'il a épuisé son quantum de temps Q0 , il est rangé dans la file F1 moins prioritaire. Lorsqu'un processus de cette file est activé (ce qui ne se produit que lorsque F0 est vide), le système lui alloue un quantum de temps Q1. S'il n'est pas encore terminé à la fin de ce deuxième quantum, il est rangé dans la file F2 affecté du temps Q2. Une file de rang i ne peut être servie que si toutes les files précédentes sont vides. Le quantum Qi augmente avec i, donc en raison inverse de la priorité. Un processus qui a traversé toutes les files sans épuiser son temps de service reste dans la file la moins prioritaire. La figure 5.5 schématise ce fonctionnement.
Si Q0 est grand on peut quasiment considérer que tous les travaux courts, dont le temps de service ts est plus petit que Q0 seront totalement satisfaits en une seule fois et jamais remis dans la file d'attente. Ceci correspond alors pratiquement au modèle SJF car les travaux les plus courts sont servis les premiers.
La priorité des travaux les plus courts est la plus grande mais en réglant les priorités des différentes files de façon plus subtile que celle que nous venons de décrire, on peut éviter les phénomènes de famine pour les processus demandant un temps long.
V-3.2. Allocation du temps dans un système en temps partagé
Quelque soit le modèle de file d'attente employé, on ne peut jamais éviter un décrochage asymptotique lorsque la demande devient supérieure à la disponibilité de la ressource. Ce phénomène est bien connu dans les systèmes multiutilisateurs où l'on peut vivre des situations fort désagréables si on n'a pas limité raisonnablement le nombre d'usagers simultanés. Cette valeur ne peut être déterminée que par tâtonnements successifs car il est impossible de connaître ![]() et ts qui varient rapidement de façon totalement aléatoire. C'est pourquoi il ne faut accorder trop de confiance aux tests généraux de tenue en charge qui sont incapables de simuler correctement ces paramètres. La seule façon d'évaluer le comportement d'un système face à ce problème est de l'utiliser en vraie grandeur ou de se renseigner auprès d'autres sites qui en font un usage équivalent. Ainsi la même machine capable de servir une centaine d'étudiants en apprentissage décrochera face à une vingtaine d'ingénieurs qui emploient de vrais logiciels d'exploitation. Des systèmes en apparence identiques, comme les systèmes Unix développés par différents constructeurs, peuvent révéler un comportement dissemblable.
et ts qui varient rapidement de façon totalement aléatoire. C'est pourquoi il ne faut accorder trop de confiance aux tests généraux de tenue en charge qui sont incapables de simuler correctement ces paramètres. La seule façon d'évaluer le comportement d'un système face à ce problème est de l'utiliser en vraie grandeur ou de se renseigner auprès d'autres sites qui en font un usage équivalent. Ainsi la même machine capable de servir une centaine d'étudiants en apprentissage décrochera face à une vingtaine d'ingénieurs qui emploient de vrais logiciels d'exploitation. Des systèmes en apparence identiques, comme les systèmes Unix développés par différents constructeurs, peuvent révéler un comportement dissemblable.
Pour essayer de préciser les résultats antérieurs envisageons un nombre d'usagers N constant. On associe un processus à chaque utilisateur. La durée moyenne nécessaire pour élaborer une requête, c'est à dire la somme du temps de réflexion et du temps de frappe sur le clavier est appelé![]() . La figure 5.6 montre comment le temps de réponse varie en fonction du nombre de terminaux en service.
. La figure 5.6 montre comment le temps de réponse varie en fonction du nombre de terminaux en service.
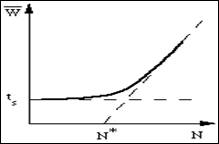
figure 5.6 : Temps de réponse en fonction du nombre N de terminaux actifs
Au-delà d'un seuil critique ![]() ,
, ![]() augmente en se rapprochant de l'asymptote de pente
augmente en se rapprochant de l'asymptote de pente ![]() . La réalité est moins simple qu'il n'y parait car
. La réalité est moins simple qu'il n'y parait car ![]() varie à tout instant. Ce résultat est théorique : il suppose une charge constante, relativement élevée, pour que le processeur soit constamment occupé, sans pour autant dépasser de beaucoup une valeur
varie à tout instant. Ce résultat est théorique : il suppose une charge constante, relativement élevée, pour que le processeur soit constamment occupé, sans pour autant dépasser de beaucoup une valeur ![]() = 1. N* indique ce seuil de saturation, c'est à dire le nombre d'usagers à partir duquel le temps de réponse
= 1. N* indique ce seuil de saturation, c'est à dire le nombre d'usagers à partir duquel le temps de réponse ![]() commence à croître de façon sensible. Nous verrons plus loin comment une augmentation de la charge, produite par un accroissement du nombre d'utilisateurs N et des temps de service demandés ts, peut conduire rapidement à un allongement important du temps de réponse et à un écroulement de la charge utile de la machine. Les performances des systèmes en temps partagé sont très sensibles à leur mode de fonctionnement. Il faut prendre ces résultats avec beaucoup de précautions car ils n'ont pas d'autre prétention que de représenter le fonctionnement moyen de machines qui doivent supporter de grandes variations instantanées de leur charge. Néanmoins ils montrent bien la difficulté du partage d'une ressource rare.
commence à croître de façon sensible. Nous verrons plus loin comment une augmentation de la charge, produite par un accroissement du nombre d'utilisateurs N et des temps de service demandés ts, peut conduire rapidement à un allongement important du temps de réponse et à un écroulement de la charge utile de la machine. Les performances des systèmes en temps partagé sont très sensibles à leur mode de fonctionnement. Il faut prendre ces résultats avec beaucoup de précautions car ils n'ont pas d'autre prétention que de représenter le fonctionnement moyen de machines qui doivent supporter de grandes variations instantanées de leur charge. Néanmoins ils montrent bien la difficulté du partage d'une ressource rare.
V-4. Partage des disques
La gestion de l'accès à un disque ne diffère pas fondamentalement de celle du processeur. Dans un cas comme dans l'autre il faut gérer au mieux l'usage d'une ressource unique : un seul processus peut accéder au disque, à la fois. Les politiques décrites précédemment peuvent encore être employées.
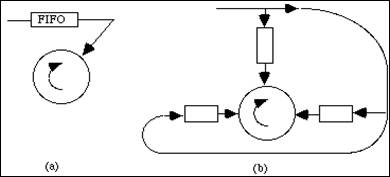
Figure 5.7 : Schéma d'accès au disque.
(a) file d'attente unique (b) N files chacune dédiée à un groupement de secteurs précis.
On peut imaginer de créer une file d'attente unique FIFO (fig. 5.7a) dans laquelle toutes les requêtes sont accumulées. Chacune est satisfaite à son tour, dans l'ordre des demandes. Cependant cette méthode, quoique simple, n'optimise pas les déplacements des têtes de lecture. Or il faut savoir que les mouvements mécaniques sont très lents par rapport au temps de cycle d'un ordinateur. L'accès au disque n'est donc pas très performant.
Les blocs qui constituent les morceaux des fichiers sont le plus souvent, sauf réservation de l'espace à la création, dispersés sur plusieurs cylindres. La succession de demandes multiplie les déplacements et allonge considérablement le temps d'accès qui n'a plus rien à voir avec les performances annoncées par le constructeur. C'est comme cela que travaillent les interfaces les plus simples, sur les micro-ordinateurs, d'où l'intérêt de réorganisations régulières des disques afin de minimiser les déplacements des têtes. Lorsque les différents blocs constitutifs d'un fichier sont regroupés sur des cylindres voisins, le temps d'accès est considérablement réduit.
|
|
| figure 5.8 : Temps d'accès au disque dans |
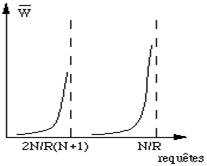
Dans les systèmes les plus sophistiqués il existe plusieurs files d'attente, chacune d'entre elles gérant un ensemble de secteurs voisins (fig. 5.7b). En fonction des blocs à lire la requête est décomposée en autant de demandes que nécessaire puis chacune d'entre elles est rangée dans la bonne file. Les demandes ne sont donc pas forcément servies dans leur ordre d'arrivée et cela nécessite une gestion des accès assez compliquée. Cependant le gain est important comme le montre la figure 5.8. Soit N le nombre de secteurs par piste, R la durée de rotation du disque, le rapport de saturation, indiqué par la position de l'asymptote qui indique le moment où le temps de réponse commence à augmenter de façon sensible, est déplacé dans un rapport (N+1)/2 lorsqu'on crée autant de files qu'il existe des requêtes obéissent à une loi de distribution de Poisson.
V-5. Partage de la mémoire
La mémoire est une ressource rare. Il n'en existe qu'un seul exemplaire et tous les processus actifs doivent la partager. Si les mécanismes de gestion de ce partage sont peu efficaces l'ordinateur sera peu performant, quelque soit la puissance de son processeur. Celui-ci sera souvent interrompu en attente d'un échange qu'il aura réclamé. Si un programme viole les règles de fonctionnement de la mémoire, il en sera de même. les performances d'un ordinateur, on mesure pour chaque programme d'un jeu de tests trois temps :
| q le temps de travail du processeur, directement proportionnel à la puissance de celui-ci |
| q le temps système qui traduit l'efficacité du système d'exploitation et des échanges avec la mémoire |
| q le temps total d'exécution, c'est à dire le temps qui s'est écoulé entre le début et la fin du programme. C'est la seule notion qui intéresse l'usager. Ce dernier temps peut être très supérieur à la somme des deux premiers si le programme testé viole les règles de gestion de la mémoire. Souvent de légères modifications du code suffisent à bouleverser les performances. Par exemple, comme nous le verrons, lorsqu'on travaille sur les éléments d'un grand tableau, il est aisé de faire varier de 30% à 50% ce temps simplement en choisissant l'ordre de manipulation des indices. |
Pour écrire des programmes efficaces il faut bien comprendre comment la mémoire est gérée.
V-5.1. Structure d'un module exécutable
Le code du programme qu'exécute un processus s'appelle un module exécutable ou load module. Nous décrirons au chapitre VI comment on le construit à partir d'un programme écrit en langage évolué, C, fortran... Il est stocké sur le disque et chargé dans la mémoire au moment de l'exécution. Le module exécutable n'est pas exactement l'image du code en cours d'exécution pour de nombreuses raisons. Tout d'abord les adresses à manipuler ne peuvent pas être connues à l'avance car un programme peut être chargé en différents endroits de la mémoire. De plus il utilise différentes ressources dont les adresses sont également inconnues jusqu'au moment du chargement : adresses des tampons, éléments de codes partagés avec d'autres processus et déjà existants dans la mémoire, bibliothèques dynamiques, localisation de nombreuses tables: mot d'état, fichiers, périphériques.... Le chargeur ou loader doit donc modifier ce code pour établir tous les liens nécessaires. Son travail dépend beaucoup de la structure du module exécutable. Nous envisagerons ici uniquement le calcul des adresses des objets internes au programme (localisation des variables, adresses de débranchement dans les tests et les appels de procédures internes...).
|
|
| figure 5.9 : Structure d'une mémoire |
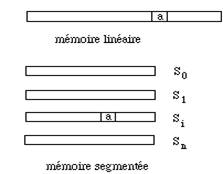
Le module peut être constitué d'un seul bloc chargé à des adresses contiguës dans la mémoire. Il suffit alors d'ajouter la valeur de l'adresse où a été placée le début de ce module, partout où une adresse apparaît dans ce code, notamment dans les débranchements, pour calculer les vraies adresses en mémoire.
Ce module peut être segmenté. Il est constitué de plusieurs morceaux ou segments, chacun chargé à des adresses contiguës. Deux segments ne sont pas, à priori, voisins dans la mémoire. Le code et les données, c'est à dire l'ensemble des constantes et des variables, sont rangés dans des segments séparés. Il existe donc au minimum deux segments. L'adresse d'un objet, à l'intérieur du programme, est obtenue par la connaissance du numéro i du segment et de la valeur a du déplacement à l'intérieur de celui-ci (fig. 5.9).
L'allocation de la mémoire comporte tout d'abord une étape où on copie le module exécutable dans la mémoire physique. Entre autre il faut :
| q gérer la mémoire physique, c'est à dire allouer les emplacements de chargement et transférer l'information. Nous évoquerons ce point dans la section 5.3 |
| q réaliser les correspondances entre adresses virtuelles et physiques. On remplace les adresses, telles qu'elles ont été calculées par le compilateur, par les vraies adresses en mémoire. |
| q assurer les protections mutuelles entre les divers éléments de mémoire alloués aux différents processus et charger le contenu des tables de contexte. |
Lorsque le module exécutable est plus petite que la mémoire physique disponible, le chargement ne présente pas de difficulté. On peut utiliser une politique d'allocation statique, comme dans le cas de DOS. La correspondance physique-virtuelle est établie au début. Il suffit d'ajouter la valeur n de l'adresse physique de chargement à toutes les adresses virtuelles du module.
|
|
| figure 5.10 : Principe des overlays |
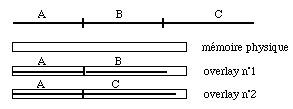
Lorsque ce module est plus grand que la mémoire physique il est encore possible d'exécuter le programme si l'on peut employer une politique d'allocation dynamique. C'est ce qu'on fait dans la technique d'overlay. Le programme est découpé en segments qui ne sont pas tous chargés simultanément. Dans le schéma de la figure 5.10, par exemple, un programme est constitué de trois segments A, B, C. On charge toujours A puis successivement B puis C. Ceci doit évidemment être prévu dans la programmation afin qu'aucun élément de B ne fasse référence à un élément de C et réciproquement. On doit également ajouter les instructions nécessaires à ces allocations. La technique d'overlay est tombée en complète désuétude depuis l'apparition de la mémoire virtuelle paginée que nous décrirons dans la section 5.3. Elle est encore employée par DOS.
V-5.2. Comportement d'un programme
Examinons maintenant comment un programme utilise les différentes adresses de la mémoire de l'ordinateur au cours de son exécution. Pour étudier ce comportement imaginons que celle-ci soit découpée en blocs physiques, appelés pages, de longueur fixe, tout comme un disque est découpé en secteurs. La taille de la page varie suivant les systèmes d'exploitation. Elle est de 512 octets dans la plupart des systèmes Unix, elle atteint 2048 octets dans les grosses machines IBM.
L'adresse d'un mot de la mémoire peut être définie par la combinaison du numéro p de la page qui le contient et d'un déplacement d qui est son adresse relative dans la page. Soit S la taille de la page. On établit simplement la valeur a de l'adresse absolue au moyen de la relation : a = p.S + d.
Des études statistiques ont montré le comportement suivant:
| q Au cours de la vie d'un processus, 75% des références concernent moins de 20% des pages. Cela signifie que les déplacements, les branchements se produisent dans un nombre réduit de pages. |
| q A un instant donné, les références observées sont le plus souvent locales. Cela signifie que la distance entre l'instruction courante et la suivante est petite. De même lorsqu'on manipule des variables elles se trouvent rangées à des adresses voisines. Lorsqu'un programme exécute une instruction dans une page de numéro pi il utilise pendant un temps ti relativement long un ensemble de pages voisines de celle-ci. Puis apparaît une période de transition très erratique avant que le processus ne recommence. |
On charge donc, dans la mémoire d'un ordinateur, de nombreuses informations qui ne sont pas immédiatement indispensables au fonctionnement du processus. Imaginons maintenant le cas où la mémoire physique disponible est plus petite que l'image virtuelle du programme. On ne peut charger qu'une partie du programme seulement. Le processus exécute un certain nombre d'instructions puis se débranche à l'adresse d'une instruction (ou fait appel à une donnée) rangées dans une nouvelle page qui n'est pas en mémoire. Il se produit alors un défaut de page.

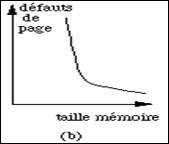
figure 5.11 : Durée de vie et nombre de défauts de page, en fonction de la taille de la mémoire
La figure 5.11 montre deux aspects du comportement statistique des programmes. Dans la figure a on a indiqué le temps qui s'écoule entre défauts de pages successifs, en fonction de la taille de la mémoire de l'ordinateur. Dans la figure b, on a indiqué le nombre de défauts de pages en fonction de ce même paramètre. Dans ces graphiques, la taille de la mémoire est normalisée en fonction de la taille moyenne des programmes qui sont exécutés. La durée de vie est l'intervalle de temps qui sépare deux défauts de page consécutifs. On remarque qu'au-delà d'une certaine valeur, il n'est plus rentable d'augmenter la taille de la mémoire car le nombre de défauts de pages ne diminue plus de façon sensible et cela n'améliore pas la durée de vie.
V-5.3. Allocation statique de la mémoire
La mémoire est allouée de façon statique, lorsque des partitions fixes sont prévues dés le démarrage de l'ordinateur. Chaque programme est chargé dans une partition différente. Lors de la copie du module binaire depuis le disque dans la mémoire, toutes les adresses sont obtenues en ajoutant celle du début de la partition.
Un défaut de page ne peut se produire puisque le programme est intégralement dans la mémoire. Dans le cas de systèmes multitâches, où plusieurs processus coexistent, l'ensemble de leurs codes doit être contenu dans l'ensemble des partitions alors que très peu de pages sont actives à un instant donné. L'ordinateur doit donc être équipé d'une très grande mémoire qui est très mal utilisée. On peut remédier à cet inconvénient en interrompant un programme puis en le déchargeant entièrement sur le disque pour réquisitionner l'espace qu'il occupait. Ce système manque de souplesse lorsque la taille des partitions n'est pas adaptée à la taille des codes que l'on veut exécuter. Il faut alors reconfigurer l'ordinateur, ce qui impose de l'arrêter. La protection entre processus est assez simple à réaliser puisqu'ils fonctionnent chacun dans des partitions séparées.
L'allocation statique de la mémoire n'est plus guère employée que dans des systèmes temps réel de commande de processus industriels où le nombre de programmes actifs simultanément est réduit. Un partitionement peut être prévu une fois pour toutes puisque ce sont toujours les mêmes programmes qu'on utilise. Ces ordinateurs sont optimisés pour réagir le plus rapidement possible aux sollicitations externes et la simplification de leur système d'exploitation apporte un gain dans leurs performances. Ils ont servis notamment pour construire des centraux téléphoniques.
V-5.4. Allocation dynamique de la mémoire
Dans les systèmes plus évolués la mémoire n'est pas partitionnée : on alloue les emplacements, dans la mémoire, en fonction de la taille des programmes à exécuter. Il faut prévoir des protections entre processus car ils fonctionnent tous dans le même espace virtuel et tout débordement intempestif de l'un d'eux risquerait de perturber le fonctionnement des autres. Cette allocation dynamique permet une grande souplesse de fonctionnement car plusieurs processus, de taille variable, peuvent coexister dans la mémoire physique et fonctionner simultanément. Il n'est plus nécessaire de prévoir à l'avance les caractéristiques des programmes à exécuter.
Un processus est constitué de plusieurs segments. Un segment est chargé dans une plage d'adresses contiguës, sinon le calcul des translations d'adresses à effectuer lors de cette opération deviendrait très compliqué. Certains systèmes exigent même que tous les segments d'un programme soient chargés simultanément. Pour permettre un fonctionnement efficace et minimiser les recherches d'adresses lors de l'exécution du processus, certains éléments fondamentaux comme les primitives les plus employées, les zones de sauvegarde du contexte ..., sont chargés à des adresses f
V-6. Mémoires hiérarchiques
Le principe de localité, c'est à dire la constatation empirique du fait que les programmes manipulent essentiellement des pages contiguës, a amené les constructeurs à introduire une hiérarchie dans les mémoires des ordinateurs. Lorsque le processeur accède à une adresse n il est statistiquement probable qu'il réclamera une adresse voisine pour des instructions ou les variables suivantes.
Une politique idéale de gestion dynamique d'une hiérarchie de mémoire est de répartir les informations nécessaires au fonctionnement d'un processus de telle façon qu'elles soient disponibles sans retard ni interruption au moment voulu. Imaginons deux niveaux adjacents de cette hiérarchie. Une bonne gestion anticipera donc les besoins en amenant du niveau bas au niveau haut le sous-ensemble d'informations dont la probabilité d'accès est la plus élevée. Le niveau haut fonctionne donc comme un cache pour le niveau bas. Ceci est parfaitement conforme au principe de localité.
La mémoire de stockage la plus rapidement accédée est dans le processeur lui-même : il s'agit des registres. Un compilateur sait reconnaître, par exemple, les deux séquences suivantes placées à une distance de quelques instructions :
a = b + c;
..........
d = a + f;
Ranger à l'adresse de a le résultat de la première instruction puis rappeler cette même adresse pour exécuter la seconde nécessite deux transferts entre le processeur et la mémoire. Le compilateur traduira ce code en :
$R = b + c;
...........
d = $R + f;
a = $R;
où $R symbolise un registre. La même séquence demande un transfert de moins.
Le deuxième niveau de mémoire est constitué par les caches de code et de données attachés au processeur. Il y accède sans utiliser le bus (dans les processeurs modernes ils sont intégrés dans la puce). Lors d'une demande de chargement d'une instruction ou d'une donnée, le processeur vérifie que l'information n'est pas déjà dans un cache. Si oui il abandonne cette demande, sinon il procède normalement. Comme la préparation d'un transfert est plus longue que le transfert lui-même, il déplace simultanément tout un bloc d'instructions ou de données qui sont copiés dans les caches pour être éventuellement utilisées au cours des cycles suivants. Le calcul est très fortement accéléré tant qu'on travaille dans ces mémoires. Les gains de performance peuvent atteindre 2 ou 3. La taille des caches doit être en relation avec la puissance du processeur et du temps nécessaire aux échanges sur le bus : trop petits ils ne suffisent pas à alimenter un processeur rapide qui est alors souvent interrompu par des accès forcément plus lents à la mémoire. Des variations de 2 à 3 dans la vitesse d'une machine peuvent être mesurées en fonction de ce paramètre. Ceci est bien évidemment très dépendant des programmes. L'utilisateur peut optimiser le code de son programme pour exploiter au mieux cette possibilité. Il faut, entre autre, couper les boucles trop longues en plusieurs de façon que chacune tienne dans le cache, manipuler des éléments de tableaux voisins et de façon plus générale respecter le principe de proximité.
Aux niveaux les plus bas on trouve la mémoire puis les disques. Les tampons utilisés pour les entrées-sorties sont les caches des disques. Les coupleurs de bonne qualité comportent également une mémoire locale qui joue également un rôle dans cette hiérarchie. Cet ensemble est résumé dans la figure 5.17. Les numéros indiquent la position hiérarchique de la mémoire considérée.
Les ordinateurs qui doivent manipuler de grosses bases de données disposent de disques qui sont eux-mêmes de véritables machines. La mémoire de ces dernières joue le rôle de cache afin de limiter les accès aux disques qui sont trop lents. C'est là qu'on recherche d'abord l'information. Lorsqu'elle ne s'y trouve pas, on la lit sur un disque c'est tout un bloc qui est transféré et placé dans la mémoire de la machine de stockage.
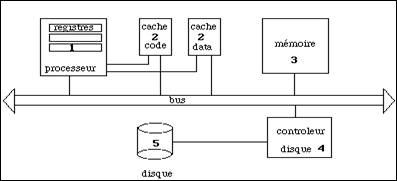
Figure 5.17 - La hiérarchie des mémoires dans un ordinateur
L'utilisation de caches ne présente pas que des avantages. Ceci complique le chargement du contexte d'un processus puisqu'il faut tenir compte du contenu de ceux-ci. Les transferts avec la mémoire sont moins efficaces car il faut consulter leur contenu et les charger en parallèle le cas échéant. C'est la raison pour laquelle les machines Cray n'en possèdent pas. Recherchant les performances les plus grandes ce constructeur a préféré employé des technologies de pointe plus coûteuses que ralentir le fonctionnement. En fait la mémoire de ces machines n'est qu'un très grand cache mais cette solution est onéreuse.
Comme toujours en informatique la réalisation d'une machine et de son système d'exploitation est un compromis entre efficacité, complexité et coût.