![]()
![]() Chapitre 6
Chapitre 6
Utilitaires
Nous décrirons dans ce chapitre un ensemble de logiciels qui ne font pas partie stricto-sensus du système d'exploitation. Ils ne sont pas indispensables au fonctionnement de l'ordinateur. L'utilisateur d'un programme n'a pas à les connaître et ils ne font pas toujours partie de la livraison minimale des logiciels d'exploitation. Les vendeurs camouflent souvent de pseudo-rabais en ne les fournissant pas. Ils facilitent la gestion de la machine et sont souvent indispensables : par exemple les logiciels de sauvegarde permettent de reconstituer l'information au cas où il arriverait un accident lorsque le contenu d'un disque est perdu et ceux fournis par les tierces parties sont souvent de meilleure qualité. Ces utilitaires sont indispensables pour certaines catégories d'utilisateurs : ainsi on imagine mal qu'un développeur puisse ne pas disposer de compilateurs. Il ne pourrait pas écrire de nouvelles applications.
Il est difficile d'en dresser une liste exacte et nous nous limiterons à décrire brièvement quelques uns que nous considérons comme essentiels.
VI-1. Utilitaires de développement
VI-1.1. Les outils
La compilation et l'édition des liens recouvrent toutes les opérations nécessaires pour transformer un programme écrit en langage évolué (fortran, langage C...) en un module binaire exécutable dans la mémoire de l'ordinateur.
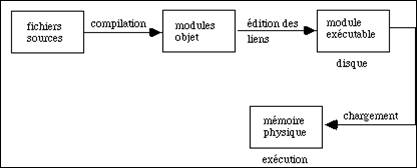
Figure 6.1 - les différentes étapes de production et d'exécution d'un programme
La compilation est la traduction en langage binaire de chaque module (fonction, sous-programme, procédure...).
L'édition des liens ajoute des modules binaires, contenus dans des bibliothèques, employés par des fonctions du programme : fonctions d'entrées-sorties, mathématiques..., ainsi que l'établissement des connexions pour enchaîner leur fonctionnement.
Ces deux étapes sont souvent effectuées l'une après l'autre, bien qu'elles correspondent à des actions très différentes et sont cachées dans une procédure commune de compilation - édition des liens. Suivant les options de la procédure on passe par l'une, l'autre ou ces deux étapes.
Le débogueur (ou debugger en anglais) est un outil de mise au point qui permet de tester le fonctionnement d'un programme. Il est possible de vérifier les valeurs de variables internes au programme sans avoir à ajouter des ordres d'écriture, de suivre pas à pas les instructions exécutées et plus généralement de controler le fonctionnement du programme. Certains débogueurs possèdent un interface graphique qui facilite leur utilisation. Nous décrirons leurs fonctions essentielles.
Il existe également des utilitaires qui permettent de garder trace des différentes modifications d'un programme, lors de son développement. Ils sont standards dans le monde Unix. Nous n'évoquerons pas ces derniers ici.
|
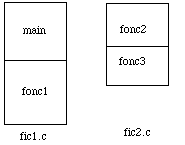
figure 6.2 : Programme source |
On imaginera, pour illustrer ces explications, un programme rangé dans deux fichiers de nom fic1.c et fic2.c (pour les systèmes Unix l'extension .c est obligatoire pour pouvoir compiler des sources écrites en langage C). Cette extension serait .f s'il s'agissait de Fortran. Le fichier fic1.c contient (fig. 6.2) le code du programme principal appelé main ainsi que celui d'une fonction appelée fonc1. Le fichier fic2.c contient: les fonctions fonc2 et fonc3. |
|
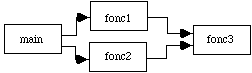
figure 6.3 : Organigramme du programme |
La figure 6.3 représente un organigramme possible: main appelle fonc1 et fonc2 successivement. fonc3 est appelée par fonc1 comme par fonc2. Cet organigramme n'est mentionné que pour illustrer le fait que le code complet d'un programme peut être rangé dans plusieurs fichiers. Il n'a aucun intérêt par lui-même. |
VI-1.2. Compilation
Le compilateur traduit les différents modules (main, fonc1, fonc2...) en code binaire. Chaque fonction est analysée séparément sans référence aux autres. Le compilateur reconnaît les erreurs de syntaxe et peut optimiser, selon les options choisies, le code produit. Il est capable de véritables réécritures qui peuvent se traduire par des gains de temps considérables lors de l'exécution. Les résultats sont rangés dans des fichiers d'extension .o, appelés modules objets. A chaque fichier source correspond un module objet différent : fic1.o et fic2.o. Chaque module contient le codes binaire des fonctions que contenait le fichier source: main et fonc1 dans fic1.o, fonc2 et fonc3 dans fic2.o. Sauf option particulière, le compilateur n'effectue pas d'analyse interprocédurale. Chaque module est considérée comme une entité indépendante.
A ce stade on n'a pas ajouté le code des fonctions déjà compilées et rangées dans d'autres modules ou des bibliothèques, modules objets de structure spéciale, qui contiennent les codes binaires de fonctions souvent employées (entrées/sorties, mathématiques...). Le code binaire généré contient notamment des indicateurs qui marquent tous les appels à des fonctions mais ne précisent pas comment effectuer les débranchements nécessaires pour enchaîner leur exécution. Ceci est le rôle de l'éditeur de liens ou linker.
On trouve, à l'intérieur du code généré par le compilateur, pour chaque fonction, des tables qui contiennent
|
|
|
|
|
Les compilateurs C possèdent une caractéristique supplémentaire qui n'existe pas forcément dans les autres langages. Ils effectuent une première passe en appelant un pré compilateur qui possède ses propres instructions, indiquées par des lignes qui commencent par le symbole #. Ceci permet d'ajouter le code contenu dans d'autres fichiers (include), d'éliminer des morceaux de code de façon conditionnelle, de définir des constantes... Le code source généré est rangé dans un fichier temporaire et c'est lui qui est compilé. Rien n'empêche d'utiliser un pré compilateur pour des langages qui n'en possèdent pas comme Fortran notamment.
Le code binaire généré par les compilateurs modernes est le même quelque soit le langage source, ce qui permet, avec certaines précautions, de créer des programmes en liant des fonctions écrites dans des langages différents.
VI-1.3. Edition des liens
L'utilitaire d'édition des liens analyse les informations contenues dans les modules objets et crée, à partir de ces données, le module exécutable.
Il identifie tous les appels, à des fonctions, contenus dans l'ensemble des modules objets qu'il doit lier. Il établit les débranchements nécessaires pour enchaîner leur code et recherche, dans les bibliothèques qu'on lui a indiquées, le code d'autres fonctions. Lorsqu'il les trouve il les ajoute au module exécutable qu'il construit et calcule les débranchements nécessaires à leur utilisation. Dans le schéma de la figure 6.3 il ajoute les codes binaires de fonc2 et de fonc3 à celui de main et calcule les débranchements nécessaires à leur enchaînement. L'analyse de ces fonctions l'amène à rechercher le code de fonc3 qu'il trouve dans fic2.o. Il l'ajoute également et calcule l'adresse de branchement pour exécuter cette fonction. Par définition la première instruction du programme principal possède l'adresse zéro.
Il recherche également les fonctions contenues dans les bibliothèques dont on lui a précisé l'emplacement. L'éditeur de liens explore certaines bibliothèques automatiquement, comme celles qui contiennent les fonctions d'entrées-sorties. Cependant le développeur doit indiquer explicitement le nom de certaines. Explorer systématiquement toutes les bibliothèques seraient beaucoup trop long. De plus certaines n'ont d'utilité que dans certains contextes. Imaginons, par exemple, que l'on écrive un programme qui pilote le fonctionnement d'une carte d'acquisition de données connectées au bus de l'ordinateur. Son constructeur aura fourni une bibliothèque spécialisée qui contient l'ensemble des primitives de contrôle de la carte. L'exploration de cette bibliothèque n'aura de sens que lorsqu'on écrit un module qui va utiliser celle-ci. Il conviendra donc de la mentionner dans la liste des options de l'éditeur de liens, uniquement pour les programmes qui l'emploie. Il est inutile, par contre, de préciser le nom de bibliothèques standard comme celle qui contient les ordres d'entrées-sorties ou les fonctions intrinsèques au langage employé.
Le nom du module exécutable créé est fourni par le développeur lors de l'appel à l'éditeur de liens. Le code créé par l'éditeur de liens est rangé dans un fichier qui porte ce nom. Pour exécuter le programme réalisé, il suffit de taper le nom du module exécutable. La suite des opérations a été décrite au chapitre V.
VI-1.4.Les pièges du compilateur et de l'éditeur de liens
Lorsque le code source contient des erreurs de syntaxe le compilateur les signale. Il donne une explication en anglais et indique la ligne où il a diagnostiqué l'erreur. Il peut même, dans certains cas, tenter de les corriger. Il ne faut jamais lui faire confiance et corriger soi-même les erreurs détectées. Les diagnostics ne sont pas toujours très clairs. Ils peuvent même avoir pour origine une erreur antérieure : lorsqu'une ligne de code est erronée le compilateur l'ignore, ce qui peut causer des erreurs par la suite. Ainsi une déclaration de variable mal écrite est supprimée et est à l'origine d'un diagnostic d'erreur chaque fois que la variable est utilisée.
Une bonne règle est de corriger les premières erreurs puis de recompiler. Souvent beaucoup d'autres diagnostics vont également disparaître.
L'éditeur de liens peut également faire apparaître des erreurs. A ce stade les explications sont beaucoup moins aisées. Souvent l'éditeur de liens précis qu'il n'a pas trouvé certaines fonctions parmi les bibliothèques qu'il a exploré alors qu'on pense lui avoir fourni une liste complète.
En Fortran la cause la plus probable est une variable dimensionnée qu'on a oublié de déclarer et que le compilateur a interprété comme une fonction. Ceci est impossible en langage C où chaque fonction doit posséder un prototype.
Imaginons, en Fortran, une variable dimensionnée qui aurait du être déclarée mais a été oubliée. Par exemple :
real variable(10,20)
Il s'agit d'un tableau de 10 lignes et 20 colonnes mais si son nom n'apparaît pas à gauche d'un signe "=" le compilateur ne peut pas remarquer cette faute. Il comprend son code, chaque fois qu'il apparaît, comme le nom d'une fonction possédant deux arguments. Il crée donc le module binaire en indiquant un point d'appel à chaque usage de ce tableau. L'éditeur de liens l'enregistre dans sa table mais ne peut jamais, sauf exception, le retrouver dans aucune de ses bibliothèques. Il fournit donc un diagnostic juste en indiquant qu'il lui manque une bibliothèque! On évite cette difficulté en ajoutant à toutes les fonctions et sous-programmes l'instruction
implicit none
Qui oblige à déclarer toutes les variables.
La deuxième cause d'erreur, commune au langage C et au Fortran est plus subtile. Une fonction de bibliothèque peut légitimement nécessiter un lien avec une autre fonction. Lorsque cette deuxième fonction est contenue dans une autre bibliothèque que l'éditeur de liens a déjà parcourue il ne peut pas la trouver car il explore l'ensemble des bibliothèques une seule fois, de façon séquentielle. Il indique donc un diagnostic d'erreur. L'ordre d'exploration des bibliothèques peut donc être important. Parfois il n'y a pas d'autre solution que d'indiquer deux fois le nom d'une même bibliothèque pour l'explorer à deux reprises lors de la création des liens!
VI-1.5. La mise au point d'un programme
Lorsque le module exécutable est créé on passe à la phase de vérification. Il faut, dans la mesure du possible, employer des jeux de données particuliers qui peuvent permettre de prévoir sinon le résultat du moins son ordre de grandeur. Le programmeur doit avoir une bonne connaissance du problème traité pour savoir choisir ces jeux de données et interpréter les résultats. C'est la raison pour laquelle les chefs de projet doivent être également des spécialistes du domaine d'utilisation envisagé: un programmeur scientifique doit être un physicien, un électronicien..., un programmeur de gestion doit avoir de solides compétences dans ce domaine.
Si le programme ne fonctionne pas ou s'arrête sur un diagnostic la seule méthode de débogage (de l'américain bug qui désigne un vilain insecte) est d'écrire des résultats intermédiaires. Le débogueur est un outil précieux pour cela. Lorsqu'un programme s'arrête sur erreur il permet de connaître l'instruction précise où l'événement s'est produit (cela demande d'utiliser des options adéquates à la compilation).
Lorsqu'on a des doutes sur la logique d'exécution il permet :
|
|
|
Lorsqu'on pense que certaines variables prennent des valeurs erronées il permet :
|
|
|
Il existe d'autres fonctions plus subtiles qui permettent de connaître les valeurs des registres, des piles... Un débogueur peut également permettre de vérifier que les indices des variables dimensionnées restent dans leur plage de validité.
Le principal inconvénient des débogueurs est qu'ils ralentissent considérablement l'exécution. Ceci interdit leur usage pour les programmes qui calculent longtemps, ceux qui ne peuvent être exécutés qu'en batch notamment. Dans ce cas le programmeur doit trouver ses propres méthodes pour vérifier et tester son logiciel.
VI-2. Organisation logique des fichiers
L'organisation logique à l'intérieur des fichiers ne relève pas rigoureusement des systèmes d'exploitation mais plus souvent des langages et bibliothèques logicielles qui les complètent. Pour Unix la réponse est très simple : il n'existe rien. Les fichiers sont de simples suites d'octets non structurés. Seule la fin de fichier est reconnue. Le reste, c'est à dire la signification des octets qui se succèdent, est l'affaire des langages et des programmations. Ainsi les fichiers écrits en Fortran contiennent des informations dont la structure n'est reconnue que par ce langage. Il n'est même pas garanti que celle-ci soit commune à différentes réalisations du compilateur sur différentes machines.
Néanmoins il est indispensable d'aborder ici le problème des structures de fichiers car la limite entre applicatifs et système d'exploitation est ténue et les fichiers sont une part importante du fonctionnement des ordinateurs. Nous n'évoquerons que les plus classiques car elles sont une bonne illustration de ce qui existe.
VI-2.1. Accès séquentiel
Un fichier est constitué d'un ensemble d'informations groupées par articles. Chacun d'eux correspond à une instruction d'écriture dans le programme qui a créé cette information. L'accès est séquentiel si, pour accéder à l'article rangé à la n ème position, il est nécessaire de lire les n-1 articles précédents. Le modèle qui correspond le mieux à cette organisation est la bande magnétique : il faut lire l'information depuis le début pour accéder à celle que l'on désire. Cette organisation est couramment employée sur disque bien que la structure de ce support permette d'autres accès que nous détaillerons par la suite.
Quoique simple à créer (il suffit de simples ordres d'écriture) cette organisation présente de sérieux inconvénients.
|
|
|
VI-2.2. Accès direct
Imaginons une organisation où tous les articles auraient la même longueur. On peut alors calculer l'adresse, dans le fichier donc sur le disque, d'un article dont on connaît le rang. Si cette longueur fixe est de m octets, l'adresse a de l'article de rang n est a = (n - 1)*m. Pour accéder directement à l'article n, il suffit alors de se déplacer de a octets depuis le début du fichier. Encore faut-il connaître n.
Notons qu'il est impératif que la longueur de tous les articles soit la même. On doit prévoir, au moment de l'écriture du programme, la longueur du plus grand et l'utiliser pour tous, ce qui peut conduire à de grands gaspillages d'espace. Il est possible de remplacer ou d'ajouter un article car aucune marque de fin de fichier n'est inscrite après une écriture. Ceci permet de faire évoluer le fichier sans avoir à le reconstruire entièrement comme dans le cas des fichiers séquentiels.
La rapidité d'accès est considérablement améliorée mais le programmeur doit gérer le calcul de l'adresse. Il doit définir un algorithme de gestion de la clef d'accès. Nous présenterons ici les plus connus, parmi l'immense variété qu'on peut imaginer.
VI-2.2.1. Clef univoque
On parle de clef univoque lorsqu'on peut associer directement une information à l'adresse de l'article dans le fichier. Par exemple, une société de distribution attribuera un numéro d'abonné à chacun de ses clients. Ce nombre indiquera directement le rang de l'article où sont rangées les informations correspondant à cette personne. La clef est univoque car elle est unique pour chaque client. On dispose des procédures de base :
- lire (clef, info)
- écrire (clef, info)
- supprimer (clef
L'article est identifié par sa clef. info est sa valeur. Pour le supprimer il suffit de mettre à blanc ou à une valeur prédéfinie son contenu.
A partir de celles-ci on peut créer les procédures suivantes :
- modifier (clef, info) qui est équivalente à l'enchaînement :
lire(clef, info);
modifier_en_mémoire(info);
écrire(clef, info);
- ajouter (clef, info).
Cette procédure gère la validité de la clef avant d'écrire info à sa place, c'est à dire qu'elle vérifie qu'il n'existe pas d'information déjà enregistrée à l'adresse correspondant à clef. Elle équivaut à :
lire(clef, info);
if (info==NULL) {
écrire (clef, info);
} else {
message_d'erreur();
}
Toute la difficulté est dans la gestion univoque de la clef. Elle est simple lorsqu'il s'agit d'un numéro d'abonné mais ceci n'est pas suffisant dans la plupart des cas. Des méthodes plus sophistiquées incluent un algorithme de gestion de celle-ci.
VI-2.2.2. Clef de hachage
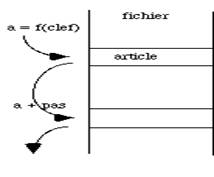
Le principe de l'accès à clef de hachage est d'ajouter un procédé aléatoire pour calculer la valeur de la clef soit en fournissant une chaîne de caractères soit à partir d'une partie de l'information contenue dans larticle. Cette information est appelée clef primaire. Si la fonction aléatoire est de bonne qualité, les valeurs obtenues pour la clef, sont bien dispersées d'où le nom d'adressage dispersé ou de hash-coding. Dans le cas d'un fichier contenant des informations sur des personnes la clef pourrait être le champ qui, dans l'article, contient le nom et le prénom. Une fonction aléatoire f(clef_primaire) calcule la valeur a de la clef.
Le choix de la fonction f(clef_primaire) présente plusieurs difficultés. La première est que le calcul doit être rapide. Les valeurs a doivent correspondre à un intervalle numérique raisonnable car elles constituent toute l'étendue possible du fichier. Considérons, par exemple, une clef primaire qui serait un nom de personne écrit sur 30 caractères au maximum. En ne distinguant pas les majuscules des minuscules et en ignorant les autres symboles éventuellement inclus dans les noms, on se limite à 26 valeurs possibles pour chaque caractère. Il y a donc à priori 2630 combinaisons possibles. On ne peut pas réserver la place pour un fichier de 2.1042 articles! La fonction de recherche f devra donc réduire cet intervalle à une valeur raisonnable tout en évitant au maximum les cas où des clefs primaires différents aboutiraient à la même valeur a de la clef.
La fonction idéale doit posséder les propriétés suivantes :
- 0 <= f(clef) < n où n est la taille du fichier (en nombre d'articles).
- f(clef1) != f(clef2) si clef1 != clef2.
Ces deux conditions sont évidemment impossibles à réaliser simultanément. On ne peut pas construire une fonction univoque et éviter des ambiguïtés ou collisions, c'est à dire des cas où des clefs primaires différentes généreraient la même valeur a pour la clef d'accès. Il faut gérer ce cas.
|
figure 4.10 : Gestion des collisions |
Envisageons tout d'abord le cas d'une écriture. Avant d'écrire à la position a obtenue par la fonction f, on vérifiera que l'article n'est pas déjà rempli, c'est à dire que son contenu ne correspond pas à une valeur prédéterminée (on voit que le fichier doit être initialisé avant tout usage). Si tel est le cas, on recherchera la première position libre, en ajoutant à la valeur calculée a de la clef un incrément prédéfini. La valeur de cet incrément doit être première avec la taille du fichier et le calcule des nouvelles clefs doit être fait, modulo la taille du fichier, afin d'être sûr de balayer successivement toutes les positions possibles (fig. 4.10). |
L'algorithme correspond à la séquence suivante :
flag = FALSE;
/* calcul de la clef à partir de la clef primaire*/
a = f(clef_primaire);
/* recherche d'un article libre */
while (flag == FALSE) {
/* lire l'article puis extraire la valeur de la clef primaire qu'elle contient*/
lire(a, info);
extraire (clef1, info);
/* vérifier qu'elle correspond bien à la clef demandée */
if (clef1 != clef) {
/* sinon incrémenter la valeur de la clef modulo la taille du fichier */
a = (a + pas)%taille;
} else {
flag = TRUE;
}
}
critère d'arrêt à cette procédure qui peut boucler indéfiniment.
Le choix de l'algorithme f(clef) est évidemment crucial. Cependant il est simples. En considérant une clef primaire constituée d'un nom rangé sur n+1 caractères et en utilisant comme fonction de hachage f :
a = ![]() atoi(clef[i])*position modulo la taille du fichier.
atoi(clef[i])*position modulo la taille du fichier.
où atoi() est la fonction qui retourne la valeur ASCII d'un caractère clef[i].
Le taux moyen de collision par accès ne dépasse pas 1,5 pour un fichier contenant 40 000 articles et prévu pour 70 000 articles au maximum.
VI-2.2.3. Fichiers indexés
Les fichiers à clef de hachage présentent l'immense inconvénient que tout tri ou ordonnancement est long et fastidieux puisqu'il faut analyser séquentiellement les articles rangés aléatoirement.
Dans un fichier indexé l'ensemble des clefs est ordonné et rangé séparément. La relation entre les clefs et les adresses des articles est établie au moyen d'une table d'index (fig. 4.11) qui peut être incluse ou séparée du fichier des articles. La manipulation des articles est aisée car elle se fait à travers de tables rapides à consulter. On peut réorganiser, trier facilement toujours au moyen de ces mêmes tables.
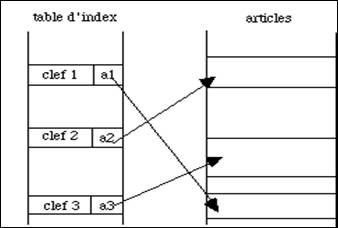
Figure 4.11 - Fichier indexé à une table d'index
Il existe des algorithmes d'organisation des tables variés en fonction de l'usage prévu. On peut accélérer les recherches en organisant cette table de manière arborescente. Un fichier indexé est fragile : il suffit de détériorer la table pour perdre l'information correspondante. Pour se prémunir contre les accidents, il faut organiser une certaine redondance, par exemple prévoir dans chaque article un pointeur vers l'entrée correspondante de la table des index. Si la table est abîmée il sera possible de la reconstruire en analysant l'ensemble des informations.
VI-2.3. Bases de données
Les bases de données requièrent l'usage de clefs d'accès multiples. La description de leur organisation fait l'objet d'ouvrages consacrés à ce seul sujet. Nous nous proposerons seulement d'en donner un exemple.
Imaginons une base bibliographique qui contienne pour chaque article :
-les noms des auteurs
-un résumé
-les références bibliographiques (année, page et numéro de la revue)
-journal et éditeur
Les références sont uniques car un article scientifique apparaît dans un numéro précis d'une revue. Il n'en est pas de même des auteurs et de l'éditeur. Un auteur peut avoir écrit plusieurs articles, un journal contient les références de nombreux auteurs. Nous étudierons une solution à ce problème pour les auteurs uniquement.
On construit trois tables d'index séparées pour les auteurs, les éditeurs et les références. A l'intérieur de chaque article on prévoit deux pointeurs afin de créer une liste circulaire des ouvrages et des auteurs (fig. 4.12).
A partir d'une première valeur dans la table des auteurs, on retrouve rapidement un premier ouvrage de Paul, puis par les pointeurs successifs, l'ensemble de ses publications. Un deuxième pointeur permettent de parcourir cette liste en sens inverse. Seul le pointeur avant est montré dans ce dessin. Il permet de reconstruire cette structure au cas où un des pointeurs serait détérioré.
Ce choix est tout à fait critiquable : il optimise la recherche de l'ensemble des ouvrages d'un auteur, ce qui n'est pas forcément l'usage le plus utile de cette base de données. Cet exemple montre que les organisations sont très dépendantes du but recherché et qu'il n'existe pas de structure générale. Par exemple la recherche des ouvrages publiés par un éditeur ne semble pas aisée.
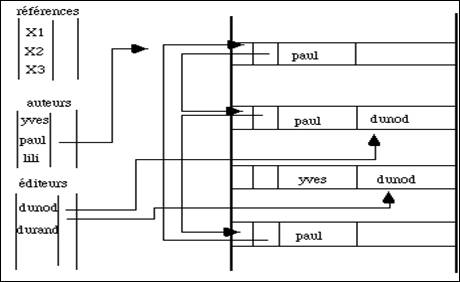
Figure 4.12 - Structure à trois tables d'index
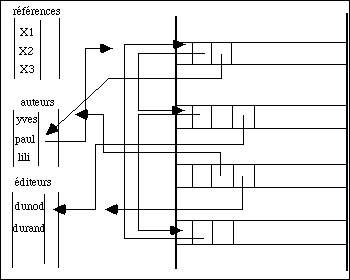
Figure 4.14 - Même base que dans la figure 4.13 optimisée pour la recherche sur critères des tables.
Cependant cette présentation est redondante: les noms d'auteurs apparaissent à la fois dans la table d'index et dans les enregistrements. Ceci augmente la taille des articles donc de la base. Ceci est également vrai pour les autres tables. On peut remédier à cela grâce à une organisation inversée où chaque enregistrement contient seulement des pointeurs sur les tables (fig. 4.13). Les noms, les éditeurs ... n'apparaissent plus en clair dans chaque article et sont remplacés par des pointeurs sur les tables correspondantes. Cette structure correspond à un usage différent du précédent. Elle permet des recherches très rapides sur les critères de définition de la base : auteurs, éditeurs, références, très lente au contraire dans l'analyse complète d'un enregistrement.
Il n'existe donc pas de structure optimale. Certaines sont plus efficaces que d'autres, indépendamment de la qualité de leur programmation, pour un usage donné mais jamais dans tous les cas.
VI-3. Sauvegardes et archivage
Les utilitaires de sauvegarde permettent de créer des copies multiples d'un même fichier ou d'une partition d'un disque afin de pouvoir recréer l'information en cas d'accident : destruction involontaire d'un fichier ou problème matériel sur le support.
Les utilitaires d'archivage déplacent des fichiers. Les informations ne sont plus utilisées mais pour différentes raisons (juridiques, usage ultérieur éventuel...) on désire les conserver. Il n'est plus nécessaire de les garder sur un support à accès immédiat et on peut les placer sur un autre, souvent plus lent en temps d'accès mais moins onéreux (bandes magnétiques, disquettes, CD-ROMs...). Il est indispensable de maintenir une base de données des archives afin de pouvoir les retrouver rapidement. Nous ne les évoquerons pas ici car ils dépassent le cadre normal du système d'exploitation.
Des outils nécessaires à l'établissement de procédures de sauvegardes font, le plus souvent, partie de la livraison du système d'exploitation. Il reste néanmoins à les mettre en uvre. De meilleurs existent soit chez d'autres fournisseurs soit dans le domaine public. Les utilitaires d'archivage sont, le plus souvent, toujours un supplément. Les sauvegardes sont partie intégrante de la sécurisation d'un système d'exploitation.
On distingue trois aspects dans la sécurité.
Le contrôle des accès a déjà été évoqué. Un fichier ne doit être visible que pour les personnes et les applications qui doivent l'utiliser. Ceci est facile à exprimer, plus délicat à réaliser et surtout à vérifier. Certains utilitaires peuvent aider à faire un audit mais leurs diagnostics doivent être lus avec prudence dans des systèmes aussi complexes qu'Unix. Il est néanmoins possible de sécuriser une machine mais ceci demande une grande rigueur et rend son usage moins souple. Dans le cas des micro-ordinateurs ceci est impossible car il n'existe pas de procédure d'identification fiable ni de notion de propriété pour les fichiers.
La sécurité physique interne consiste en la vérification de l'intégrité de l'information. Dans le cas des micro-ordinateurs on évitera d'introduire un logiciel inconnu pour éviter la prolifération de virus. On installera un logiciel antivirus et on analysera tout nouveau progiciel même lorsqu'il provient d'une source officielle réputée sure.
Enfin les sauvegardes reviennent à multiplier les copies, sous diverses formes, pour pouvoir rétablir une information perdue.
VI-3.1. Sécurité physique interne
Elle est réalisée à la fois de façon matérielle mais aussi logicielle.
Dans tout système de bon niveau il existe des bits supplémentaires, derrière chaque octet, pour contrôler et reconstruire une information détériorée lors d'un transfert sur le bus. Les possibilités d'autocorrection dépendent du nombre de bits prévus. Cela explique en partie les différences de prix, à performances équivalentes, entre machines. Il ne faut pas attendre la même sécurité d'un micro-ordinateur et d'une station de travail de haut de gamme même si leurs performances ne paraissent pas très éloignées. On trouvera dans les ouvrages consacrés aux télécommunications des chapitres entiers consacrés aux algorithmes d'autocorrection très vitaux dans ce domaine. Dans les installations les plus sensibles on installe des dispositifs miroirs : l'information est écrite simultanément sur deux disques. Si l'un d'eux tombe en panne, le second prend le relais. Ceci peut s'appliquer aux ordinateurs eux même mais il faut alors régler des problèmes de synchronisation délicats. Si plusieurs machines doivent aboutir à une prise de décision encore faut il qu'elles fournissent leurs informations dans les mêmes délais.
Au niveau logiciel on peut organiser l'information de façon à pouvoir la restaurer en cas de disparition. DOS permet de récupérer un fichier effacé par erreur. Encore convient-il de s'y prendre assez rapidement. Ceci est plus délicat pour un système interactif comme Unix ou de nombreuses applications accèdent simultanément aux disques et utilisent immédiatement un espace libéré. Dans le cas de bases de données leur structure devrait prévoir, par exemple, des pointeurs à la fois sur les articles précédent et successeur ainsi que des copies des fichiers d'index de façon à pouvoir rétablir la cohérence de la base en cas d'accident.
En dernier lieu tous les systèmes d'exploitation incluent des utilitaires de diagnostic, de vérification et de reconstruction dont l'efficacité est plus ou moins grande.
Il n'existe pas de méthode unique pour assurer la sécurité de l'information. On l'obtient par la mise en uvre d'un ensemble de procédures qui doivent être appliquées avec la plus extrême rigueur.
VI-3.2. Sauvegardes
La sauvegarde de l'information consiste en la recopie à intervalles régulier des fichiers sur un autre support. Ce sont des opérations fastidieuses, sans intérêt aucun, qui bloquent totalement ou partiellement l'usage d'une partition disque. Personne n'est donc enclin naturellement à y prêter attention. Ces opérations sont pourtant primordiales. Les pertes financières annuelles des compagnies, que des sauvegardes efficaces auraient pu éviter, sont mal connues mais se chiffrent en milliards de francs.
La règle d'or du responsable informatique est:
"les utilisateurs ne sauvegardent pas leurs fichiers, aussi compétents soient-ils. Il faut le faire à leur place et si possible de façon automatique."
Il faut se prémunir contre les erreurs dans les sauvegardes elles-mêmes. Un accident peut ne pas être détectée lors du transfert ou bien le support magnétique peut mal vieillir ou présenter des défauts. Deux sauvegardes sont un minimum, il est plus sage d'en prévoir au moins trois. Il faut donc recopier les informations sur plusieurs bandes ou disques successivement en recyclant les plus anciens. Nous décrirons plus loin un exemple de stratégie de sauvegarde.
Les sauvegardes ou backup sont à la limite entre système d'exploitation et applicatifs utilitaires. Néanmoins elles sont tellement fondamentales pour la sécurité et le bon fonctionnement d'une machine qu'il convient de les considérer comme un élément à part entière du système d'exploitation.
VI-3.2.1. Les différents niveaux de sauvegarde
Une sauvegarde physique est la recopie octet après octet, sur un autre support, d'un disque ou d'une partition dans son intégralité. Les fichiers ne sont pas distinguée et ceci ne peuvent servir qu'à restaurer le disque ou la partition. Il est impossible ou mal aisé de retrouver un fichier particulier. On l'emploie lorsqu'un disque a du être remplacé ou formaté.
Une sauvegarde logique copie les fichiers successivement. On peut donc les restaurer individuellement. Elle est moins rapides qu'une sauvegarde physique car le disque est parcouru dans un ordre logique. Lorsque les fichiers sont très morcelés cela nécessite de nombreux déplacements des têtes de lecture. On peut employer des critères de sélection : par exemple ne retenir que les fichiers modifiés ou créés dans un intervalle de temps donné, exclure ceux d'un type particulier, ignorer certains répertoires... Les critères retenus correspondent à des combinaisons d'opérateurs logiques plus ou moins sophistiqués selon les utilitaires. Une sauvegarde incrémentale. est la copie des fichiers modifiés ou créés depuis la date de la dernière sauvegarde. Certains systèmes incluent un bit d'archivage : celui-ci est levé à la création et lors de la modification du fichier, l'utilitaire de sauvegarde le baisse.
VI-3.2.2. Une stratégie pour un micro-ordinateur individuel
Nous imaginerons un propriétaire de micro-ordinateur seul responsable de sa machine. Il doit donc effectuer lui-même toutes les opérations de maintenance donc les sauvegardes.
Les logiciels ne nécessitent pas de recopie. Ils peuvent être installés à partir des disquettes et CD-ROMs d'origine ou des copies qu'on aura pris soin de faire avant la première installation. Rappelons que la loi n'interdit pas les copies de sauvegarde.
Lorsque la machine sert au développement de programmes il est inutile de copier les modules objets ni même les programmes compilés qui peuvent toujours être reconstitués. Cependant il ne faut pas oublier de sauvegarder les procédures de compilation (makefile...).
On ne conservera pas sur le disque des informations qui n'ont plus qu'une valeur d'archives. Elles seront stockées en plusieurs exemplaires dans des lieux différents.
On regroupera les fichiers créés dans des répertoires spécifiques de façon à pouvoir effectuer des sauvegardes sélectives aisément. En appliquant ces quelques règles on diminue considérablement le volume à sauvegarder et le temps nécessaire.
On peut alors choisir sa stratégie : sauvegardes incrémentales au moyen d'une procédure établie une fois pour toute qu'on aura soin de lancer régulièrement. La fréquence dépend de l'utilisation mais dans le cas d'une utilisation quotidienne une fois par semaine est le minimum. On peut également choisir de recopier systématiquement chaque jour les informations nouvelles ou modifiées. Dans tous les cas ne jamais oublier qu'ajouter les sauvegardes sur un même support, une seule disquette par exemple, est extrêmement hasardeux. Un support magnétique est facilement endommagé. Il faut disposer de plusieurs jeux que l'on cycle régulièrement. Ne pas oublier non plus que la durée de vie de ces supports est limitée à quelques années. On recopiera donc également, de temps à autres les sauvegardes et les archives.
Il existe des supports de capacité appréciable sur le marché qui permettent de sauvegarder de grandes quantités d'informations en rapport avec les capacités des disques modernes. Leurs lecteurs sont souvent fournis avec des logiciels qui permettent aisément de construire sa stratégie.
VI-3.2.3. Une stratégie pour un petit centre de calcul
Les sauvegardes sont la responsabilité d'un professionnel et occupent une part de son temps de façon légitime et régulière, au même titre que l'installation de nouveaux logiciels et la maintenance du système d'exploitation. Cette personne a donc réfléchi à une stratégie capable de pallier les différents accidents possibles:
|
|
|
|
|
|
|
|
|
On doit réduire au maximum les effets d'un accident et rétablir au plus vite un fonctionnement correct.
Il n'existe pas de réponse unique. Celle-ci dépend du type d'informations : les besoins d'une banque ne sont pas ceux d'un service chargé de développer des logiciels. La taille totale de l'espace disque, l'efficacité des transferts sur le réseau sont un point à prendre en considération.
Il n'existe pas de réponse unique. Celle-ci dépend du type d'informations: les besoins d'une banque ne sont pas ceux d'un service chargé de développer des logiciels. La taille totale de l'espace disque, l'efficacité des transferts sur le réseau sont un point à prendre en considération. L'exemple choisi est basé sur une expérience personnelle dans un centre devant gérer une quarantaine de micro-ordinateurs reliés à un réseau et 16 gigaoctets environ répartis sur les serveurs Unix du service.
Le support de sauvegarde est une bande 8mm (V-Dat) capable de stocker plusieurs gigaoctets. Les partitions disques (disques virtuels) ont été choisies de façon à tenir chacune sur une bande.
Chaque nuit des sauvegardes incrémentales sont effectuées automatiquement: les fichiers crées ou modifiées depuis moins de trois semaines, aussi bien sur les serveurs Unix que sur les micro-ordinateurs (s'ils n'ont pas été éteints), sont recopiées sur un disque réservé à cet usage. Le format compressé employé permet de stocker cet ensemble sur moins de 2 giga-octets.
Une fois par semaine chaque disque est sauvegardé. Les systèmes Unix ne connaissant pas la notion de sauvegardes physiques on peut y retrouver tout un système ou un seul fichier. Les bandes magnétiques sont conservées trois semaines, puis recyclées sauf la première de chaque mois. Enfin le temps passant on garde seulement une bande par trimestre (fig. 4.22).
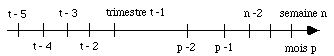
Figure 4.22 - Sauvegardes disponibles pour un disque
Cette configuration permet de répondre aux différents accidents :
|
|
|
|
|
Cette stratégie n'est pas applicable au-delà d'une capacité de quelques dizaines de giga-octets. Il faut alors utiliser de véritables systèmes de sauvegarde, rapides et possédant une grande capacité.
VI-3.2.4. Une stratégie pour un réseau de stations
Il existe maintenant des utilitaires disponibles commercialement ou dans le domaine public, qui permettent de gérer un réseau de stations. Leur principe dérive des schémas évoqués ci-dessus.
L'utilitaire distingue plusieurs niveaux de sauvegarde, depuis celui qui concerne des fichiers individuels jusqu'aux partitions disques entières. Lorsqu'un élément doit être sauvegardé il est recopié à travers le réseau, depuis la machine d'origine, sur un disque intermédiaire connecté directement au serveur de sauvegarde. Parallèlement le contenu de ce disque est recopié sur le support final, une bande magnétique le plus souvent. Les systèmes les plus sophistiqués sont capables de gérer un ensemble de bandes rangées dans un silo.
Un des problèmes clefs est d'équilibrer le volume d'informations transférées sur le réseau. Celui-ci est crucial lorsque le parc contient un grand nombre de machines. Les sauvegardes se déroulent, le plus souvent de nuit, afin de ne pas gêner l'exploitation dans la journée. L'utilitaire de sauvegarde doit donc établir une stratégie en évaluant à l'avance la quantité d'informations à transférer. Il peut avancer les dates de certains niveaux de sauvegarde afin d'équilibrer les échanges.
Le problème se complique si les sauvegardes doivent être fréquentes et se dérouler parallèlement à l'exploitation comme dans les systèmes transactionnels. On introduit souvent un niveau physique intermédiaire en écrivant l'information de façon redondante sur les disques (disques miroirs, RAID...) de façon à palier à toute défaillance physique. Mais ceci ne supprime le type de sauvegarde que nous venons d'évoquer.
Les produits disponibles se distinguent par leur souplesse d'emploi, les facilités pour ajouter ou supprimer des machines dans le parc ainsi que par les possibilités laissées à l'utilisateur final. Celui peut, dans certaines réalisations, spécifier qu'il veut ou ne veut pas voir sauvegarder ses informations. La facilité (existence d'interfaces graphiques notamment), l'efficacité des procédures pour restaurer des fichiers perdus sont également un élément qui distingue ces outils.