![]()
![]()
![]() Chapitre 2
Chapitre 2
Mécanismes d'exécution et de communication
Lorsqu'on observe un écran, il apparaît clairement que l'ordinateur mène plusieurs activités en parallèle: une horloge, par exemple, affiche l'heure pendant qu'on utilise un traitement de texte. Mieux encore on apprécie de pouvoir imprimer un document tout en continuant à écrire un autre texte. Ces activités sont gérées, en apparence, simultanément alors que la machine ne dispose que d'un processeur unique. Ces processus échangent des informations: ainsi le traitement de texte déclenche régulièrement une copie sur disque qui sauvegarde le texte écrit. Ce logiciel consulte donc l'horloge afin de déclencher ce mécanisme au moment voulu.
Le chapitre II est consacré aux notions de parallélisme entre tâches, à la compréhension de leur gestion simultanée, on parlera de leur exécution et à leurs méthodes de communications.
II-1. Notions sur les processus
On appelle activité ou processus un programme en cours d'exécution. Nous n'envisageons pas le cas où celle-ci s'exécuterait sur plusieurs processeurs simultanément. Elle se déroule de façon séquentielle: les instructions qui la composent sont chargées dans le processeur puis exécutées les une après les autres. Son état d'avancement est observable en un ensemble de points discrets avant ou après l'exécution d'une instruction. Le programme est lui-même constitué d'un ensemble de procédures. Une procédure est un ensemble logique qui se différentie essentiellement d'un programme par son fonctionnement: elle échange des informations avec d'autres procédures et elle est elle-même appelée par d'autres procédures. Un programme est donc constitué d'un ensemble de procédures et la principale enclenche les appels à toutes les autres...
L'état de la mémoire associée à un processus est défini par le contenu de zones d'adresses contiguës appelées segments. Le segment programme correspond à la partie du code qui contient les instructions. Il ne change jamais pendant toute la durée de l'activité. Les données, c'est à dire l'ensemble des variables du programme en cours d'exécution, sont rangées dans le segment de données. Le segment de données évolue sans cesse au fur et à mesure de l'exécution des instructions. La connaissance du segment de données ainsi que d'autres informations définissent l'état du processus à tout instant dans la mémoire.
A un instant donné, l'état du processeur est identifié par le contenu de l'ensemble de ses registres programmables, c'est à dire de ceux où l'on charge des informations en provenance de la mémoire et d'autres qui contiennent les résultats d'opérations correspondant au programme, ainsi que par certains à usage purement interne. La connaissance de l'état du processus et de celui du processeur est indispensable pour décrire entièrement l'avancement du processus.
II-1.1. Contexte d'un processus
Examinons le contexte des échanges entre les procédures constitutives d'un processus.
Considérons deux procédures P et Q. P déclenche l'exécution de Q.
On peut décomposer le mécanisme de leurs échanges de la façon suivante :
- préparation par P de la liste {lp} des paramètres à transmettre à Q.
- sauvegarde du contexte de P qui devra être retrouvé, après la fin de l'exécution de Q pour pouvoir continuer l'exécution de P. Ce contexte est constitué de l'ensemble des informations nécessaires à la description de l'activité de P dans l'état où elle était au moment où on l'a interrompue pour pouvoir exécuter Q. Il comprend les informations sur l'état de la mémoire: adresse des segments code et données, valeur du compteur ordinal qui pointe sur l'instruction en cours d'exécution ...
- remplacement du contexte de P par celui de Q.
- exécution de Q
Au retour, lorsque Q est terminé, le mécanisme est presque symétrique: cependant le contexte de Q n'est pas sauvegardé puisque Q a terminé son existence
- préparation par Q de la liste {lq} des paramètres transmis par Q à P.
- restauration du contexte de P
- exécution de la suite des instructions de P.
On notera que les données internes à Q sont perdues. Cela signifie que si Q est appelé une seconde fois des segments neufs de code et de données seront chargés. Toutes les données internes à cette procédure seront réinitialisées. Il n'en est pas de même pour P dont les segments continuent à évoluer à chaque déchargement-chargement et gardent mémoire des actions antérieures. On dit que les données de Q sont de type automatique
On peut imaginer un mode de fonctionnement plus symétrique où le contexte de Q est sauvegardé à chaque retour vers P. On parle alors de fonctionnement en coroutines. Dans ce cas il est indispensable de préserver les données de Q en fin d'exécution de la procédure. Leurs valeurs peuvent être préservées. Il s'agit de données de type statique.
Etudions maintenant le mécanisme de changement de contexte. Il doit:
- sauvegarder tous les éléments nécessaires au fonctionnement de P après l'appel à Q.
- transmettre les paramètres de P à Q.
- gérer les zones de travail propres à chaque procédure. Il existe différentes méthodes pour réaliser ce mécanisme d'une pile où les paramètres sont transmis par valeur comme en langage C.
A chaque appel de Q une structure, correspondant aux données qu'il faut lui transmettre, est crée. L'ensemble des valeurs de cette structure est stocké au sommet d'une pile. Au retour de Q vers P cette structure sera supprimée. Deux pointeurs sur la base et le sommet de la pile sont mémorisées. Ce mécanisme permet un appel récursif à Q puisqu'il suffit d'empiler une nouvelle structure à chaque appel. En retour de chaque appel on récupère la dernière structure la pile prévue dans le mécanisme de débranchement. Celle-ci est souvent un paramètre du compilateur.
|
|
|
|
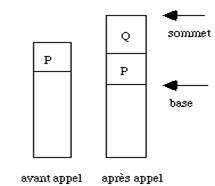
Notons qu'il suffit de connaître les valeurs des pointeurs sommet et base pour pouvoir lire tous les éléments de la structure si la première donnée indique le nombre d'éléments.
Parmi les éléments de l'environnement qu'il faut sauvegarder on notera :
* l'adresse de retour de la procédure P, c'est à dire l'adresse de la prochaine instruction de P à exécuter.
* l'adresse de la base du contexte (fig.2.1).
* les paramètres: n+1 emplacements pour les n paramètres transmis à Q. Le premier élément de la structure indique le nombre n de paramètres.
* les variables locales et l'espace de travail de P c'est à dire l'ensemble des informations indispensables au rétablissement de son fonctionnement au retour.
Dans le mécanisme de coroutine il faut imaginer un dispositif différent pour préserver également le contexte de Q, par exemple deux piles distinctes pour l'appel et le retour. Il ne faut pas oublier que les coroutines peuvent elles-mêmes inclure des procédures.
Le contexte d'un processus comprend donc un ensemble de paramètres regroupés dans les segments de la procédure en cours d'exécution (code et données) et la région d'environnement courant où sont rangés tous les éléments que nous venons d'évoquer. Cette description est incomplète mais suffisante pour notre propos.
II-1.2. Contexte du processeur
Plusieurs programmes coexistent simultanément dans la mémoire de l'ordinateur. Cependant un processeur ne peut exécuter qu'une instruction à la fois. Il est donc réservé à l'usage d'un seul processus. Il ne suffit donc pas, pour décrire l'état du système à un instant donné, de connaître le contexte de chaque processus. Il faut aussi examiner celui du processeur. Cet état est décrit par:
|
|
Ils sont regroupés sous le vocable mot d'état ou PSW (program status word) en anglais et définissent le contexte du processeur pour le processus en cours d'exécution. Notons qu'il faut également disposer d'informations sur la localisation en mémoire du processus suivant à activer.
Le mot d'état comprend des informations sur :
|
|
|
|
|
La description complète de l'activité de l'ordinateur suppose connu les contextes des différentes activités présentes en mémoire ainsi que le contexte du processeur. Changer d'activité demande donc de sauvegarder les contextes du processeur et de l'activité en cours puis de les remplacer par ceux correspondant à l'activité qui va devenir active. Ces changements sont déclenchés par des interruptions.
II-1.3. Processus et threads
Un des rôles du système d'exploitation est d'assurer l'enchaînement des activités de plusieurs processus. Le passage de l'un à l'autre peut être décrit exactement comme l'enchaînement de deux procédures (fig. 2.1). Lorsque le processus P est arrêté il faut sauvegarder, à un emplacement prévu en mémoire, son mot d'état ainsi que le contexte du processeur puis charger le mot d'état et le contexte du processeur correspondant au nouveau processus Q.
A priori les informations relatives à deux processus sont complètement séparées. Les mots d'état, les segments de code et de données sont rangés à des adresses distinctes. Le système d'exploitation doit s'assurer qu'aucun processus ne va chercher à lire ou écrire dans une zone réservée à un autre. Ceci n'est pas toujours vrai : certains systèmes n'ont pas prévu de protections, ce qui peut être très ennuyeux et fragiliser le fonctionnement de l'ordinateur. Si le processus Q modifie intempestivement les données du processus, il y a fort à parier que celui-ci ne pourra plus s'exécuter correctement! L'ordinateur a de fortes chances de s'arrêter très brutalement.
Dans certains cas on peut vouloir partager certaines informations. Imaginons, par exemple, deux processus qui exécutent le même code avec deux jeux de données différents. Il est inutile de copier deux fois le segment de code en mémoire puisque cela revient à dupliquer deux fois la même image. La connaissance du mot d'état et du contexte du processeur relatifs à chaque processus suffit pour assurer leur fonctionnement. Par contre le segment de données doit absolument être dupliqué puisqu'il n'existe aucune raison pour qu'ils soient identiques : cela signifierait que les deux processus font rigoureusement la même chose, au même instant, ce qui présenterait peu d'intérêt.
Depuis quelques années est apparue une notion nouvelle : celle de thread ou sous-processus. Chaque thread possède son propre mot d'état, son propre contexte du processeur mais partage le même segment de code et de données que le processus. Cette notion ne présente d'intérêt que pour les machines à plusieurs processeurs. Si on décompose le processus en plusieurs threads, on peut confier leur exécution à chaque processeur. Comme les threads partagent le même segment de données il faut faire très attention, lorsqu'on les programme, pour éviter tout conflit et incohérence dans leur exécution.
II-2. Notions sur les interruptions
Les interruptions sont le moyen utilisé pour stopper un processus et démarrer l'exécution d'un autre.
II-2.1. Mécanisme de commutation de contexte
Le basculement d'activité s'opère par commutation de contexte.
Imaginons le système d'exploitation le plus rudimentaire qui serait représenté par un programme unique qui gérerait à la fois le fonctionnement de l'ordinateur et les processus de l'utilisateur. Cette description ressemble plutôt à celle d'un programme dont les processus de l'utilisateur sont quelques unes de ses procédures. Le fonctionnement du système d'exploitation serait très délicat à réaliser car il n'est pas aisé de modifier ou de remplacer dynamiquement quelques procédures sans devoir relancer complètement l'exécution d'un programme. Pensez aux précautions qu'il faut prendre lorsqu'on veut remplacer une fonction dans un programme! Tout changement risquerait de perturber le déroulement des activités indispensables à la bonne marche de l'ordinateur. Par exemple, il deviendrait impossible de garantir que l'horloge puisse donner l'heure exacte. Si une procédure de l'utilisateur demandait trop de calcul au processeur, la procédure du système en charge de compter les secondes ne pourrait plus faire son travail à temps. Il faut donc prévoir un moyen plus souple pour pouvoir gérer plusieurs processus simultanément. Ceci est obtenu en décomposant le fonctionnement du système d'exploitation en plusieurs processus que l'on active ou désactive en fonction de critères qui seront décrits progressivement dans la suite de ce cours.
L'opération de commutation de contexte, préalable au changement de processus actif, est l'enchaînement indivisible des deux opérations suivantes:
- rangement du mot d'état du processus actif à un emplacement particulier de la mémoire et copie du contexte du processeur.
- chargement d'un autre mot d'état, depuis un emplacement spécifique de la mémoire, vers le processeur et récupération du contexte du processeur correspondant.
Le nouveau processus peut alors être exécuté à partir de l'état où il se trouvait lorsqu'il a été lui-même interrompu. Insistons sur le fait que cette commutation de contexte ne peut être effectuée que lorsque le processeur se trouve dans un état observable, c'est à dire entre deux instructions. La notion d'instruction est relative au microcode de la machine qui a peu à voir avec celle utilisée par le programmeur qui pense aux instructions du langage évolué qu'il emploie. Une instruction de C ou Fortran, de Java encore plus, correspond à plusieurs instructions du microcode. Le temps d'exécution de ces instructions élémentaires représente le quantum de temps minimum pendant lequel le processeur ne peut être stoppé. Les points d'arrêt sont donc les instants entre les instructions. Ils sont désignés sous le nom de point interruptible.
La commutation de contexte est liée à l'état d'un certain nombre d'indicateurs que le processeur doit consulter en chacun de ces points. On distingue plusieurs mécanismes de commutation de contexte, suivant la signification de ces indicateurs :
|
|
|
II-2.2 Les interruptions
Une interruption est un signal envoyé de façon asynchrone au processeur qui le force à suspendre l'activité en cours au profit d'une autre. La source peut être un autre processeur, un contrôleur d'entrées-sorties ou tout autre dispositif physique externe. Le programme en cours d'exécution suspend son activité au premier point interruptible. Le processeur exécute alors un programme prédéfini de traitement de l'interruption. Les causes d'interruption sont multiples. Il faut donc être capable de les distinguer et de les traiter chacune de façon spécifique. Pour cela on peut envisager diverses méthodes:
|
|
|
Chaque niveau d'interruption est affecté d'une priorité différente. En effet si deux niveaux étaient activés simultanément il se produirait un conflit. Le système d'exploitation le résout en traitant l'interruption la plus prioritaire. Ainsi l'activité qui a pour mission de contrôler la présence de la tension d'alimentation - elle n'existe pas dans toutes les machines - et de basculer le fonctionnement sur des batteries de sauvegarde doit être la plus prioritaire. Lorsqu'elle détecte une variation anormale de la tension, elle arrête immédiatement tout fonctionnement et commute l'alimentation électrique. Par convention le niveau de priorité le plus élevé est 0. La priorité décroît lorsque sa valeur augmente.
Un processus doit être protégé contre les interruptions moins prioritaires. On retarde donc volontairement la commutation de contexte jusqu'à ce que le processus le plus prioritaire ait terminé son travail ou soit lui-même interrompu par un autre plus prioritaire. Ceci est réalisé grâce à un masque d'interruption attaché à chaque processus. En chaque point interruptible lorsqu'on consulte les valeurs des niveaux d'interruption activés, ce masque cache les niveaux qui doivent être ignorés. Le masque fait partie du mot d'état. Il est lui-même modifiable par une interruption. Un niveau d'interruption peut être désarmé pour supprimer l'effet de l'arrivée d'un signal puis réarmé à la demande. Ce mécanisme est programmable.
Le schéma de fonctionnement d'une interruption est indiqué dans la figure 2.2.
|
|
|
|
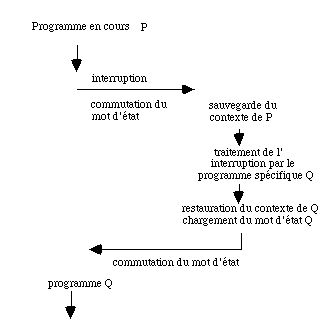
II-2.3. Déroutement, appels au superviseur
Les déroutements et les appels au superviseur sont déclenchés par une cause interne au programme en cours. Le superviseur est un élément du système d'exploitation qui contrôle l'exécution des programmes et traite les déroutements (trap en anglais) et les interruptions.
Un déroutement se produit, en particulier, lorsqu'un programme effectue une opération interdite, comme dans le cas de débordement de tableaux hors de la zone d'adresses allouée au programme, lorsque des données sont incorrectes, division par zéro par exemple, ou lorsque l'instruction ne correspond pas à un code exécutable. Les déroutements peuvent être supprimés. On peut ainsi autoriser la suite des opérations si l'erreur n'est pas trop grave: un arrondi à zéro peut être légitime et il serait stupide d'arrêter le calcul. Un déroutement peut être supprimé mais pas retardé: c'est un événement synchrone au programme en cours d'exécution pour lequel la notion de masque d'interruption ne s'applique pas. Ainsi, lorsqu'on décide de surveiller les arrondis à zéro (underflows), cela signifie que le déclenchement de l'interruption correspondante ne sera pas ignoré et déclenchera l'appel à une procédure qui signalera l'erreur et pourra même (cela dépend de la réalisation du système d'exploitation) terminer l'exécution du processus.
La gestion des traps est très variable d'un système d'exploitation à l'autre. Ceci explique qu'un programme qui semble fonctionner correctement sur une machine se révèle erroné sur une autre. Les choix par défaut sont souvent mal documentés et cela peut amener bien des surprises. Une panne hardware peut aussi, surtout avec des machines sans code autocorrecteur comme les PCs, apparaître sous forme d'un déroutement. Lorsqu'une information est mal lue dans la mémoire et que ni l'électronique ni le système d'exploitation ne sont capables de le détecter, l'instruction ou la donnée erronée ont de fortes chances de déclencher une opération interdite donc un déroutement. C'est le cas des PCs fonctionnant sous Windows.
Un appel au superviseur provoque toujours une commutation de contexte pour faire appel à la commande appropriée. C'est un événement tout à fait identique aux appels de procédures que nous avons étudié au paragraphe 1.1. Il déclenche des mécanismes de sécurité qui interdisent les opérations illicites afin de préserver l'intégrité du fonctionnement de la machine: tout appel n'est pas autorisé. Cela dépend du contexte.
II-2.4. Exemples de systèmes d'interruption
Sur les gros ordinateurs IBM de la série ES9000 le système d'interruption comprend cinq niveaux, par ordre de priorité croissante:
-Entrées-sorties.
-Evénement externe.
-Appel au superviseur.
-Déroutement
-Erreur matérielle
Comme ce nombre est tout à fait insuffisant pour pouvoir traiter tous les cas d'événements le mot d'état contient un code d'interruption sur 16 bits qui ajoute autant de niveaux logiciels. Au premier niveau celui-ci contient l'adresse du périphérique, au niveau externe on trouve par exemple l'adresse de l'horloge, d'un appareil extérieur ou de la console de l'opérateur. Le système ne distingue pas vraiment les interruptions, les déroutements et les appels au superviseur.
Les processeurs Motorola 68000 possèdent trois niveaux auxquels sont associés des groupes. Le groupe 0, le plus prioritaire, correspond aux erreurs d'adressage, de bus, de réinitialisation. Le groupe 1 gère les traces, les interruptions, les violations de protection, le groupe 2 les déroutements et les appels au superviseur.
II-2.5. Exemples d'utilisation des interruptions
II-2.5.1. Simulation d'une instruction manquante
Les processeurs qui ne possèdent pas de coprocesseur mathématique doivent utiliser des procédures pour simuler les instructions absentes, addition, multiplication portant sur les nombres flottants. Une tentative d'exécution d'un code qui n'existe pas déclenche une interruption. Elle est traitée en déroutant l'activité sur une procédure qui simule cette instruction. La procédure de simulation doit connaître l'adresse de retour dans le programme appelant. Il faut sauvegarder les mots d'état lors de cet appel. Cette procédure doit pouvoir traiter les erreurs éventuelles. Elle peut donc elle-même être déroutée.
II-2.5.2. Gestion des travaux en temps partagé
Considérons n programmes qui sont exécutés simultanément. Le processeur unique de l'ordinateur ne peut travailler que pour un seul à la fois. Il est alloué successivement aux différents processus, par tranches de temps de durée ![]() fixe. Lorsqu'un processus se termine avant la fin de sa tranche de temps ou lorsque le processeur se trouve en attente d'un autre dispositif, pour une opération d'écriture par exemple, le moniteur d'enchaînement des travaux s'intéresse au processus suivant. Ceci permet d'exploiter au mieux le processeur car il n'attend pas inutilement une ressource indisponible (fig. 2.3).
fixe. Lorsqu'un processus se termine avant la fin de sa tranche de temps ou lorsque le processeur se trouve en attente d'un autre dispositif, pour une opération d'écriture par exemple, le moniteur d'enchaînement des travaux s'intéresse au processus suivant. Ceci permet d'exploiter au mieux le processeur car il n'attend pas inutilement une ressource indisponible (fig. 2.3).
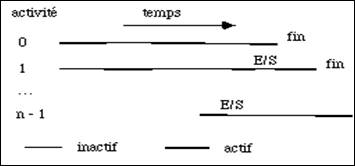
figure 2.3 Partage du temps entre activités
On alloue à chaque processus des zones de mémoire pour ranger son mot d'état ainsi que celui du processeur qui lui correspond. Le moniteur de temps partagé est plus prioritaire que toutes les taches qu'il doit gérer car il peut les interrompre alors que l'inverse n'est pas vrai. Il sauve le contexte du processus en cours et charge celui du suivant. Il arme une horloge qui déclenche à nouveau une interruption lorsque le temps alloué à ce dernier processus est à son tour écoulé.
Un ordinateur possède donc des niveaux d'interruption matériels et logiciels. Ils sont indispensables au fonctionnement de plusieurs activités en parallèle mais c'est le système d'exploitation qui les utilise. Selon la sophistication de ce dernier les possibilités seront différentes, assez pauvres pour un processeur Pentium travaillant sous Windows, infiniment plus grandes pour le même ordinateur utilisant un système Unix. Encore une fois rappelons que les possibilités de programmation des interruptions dépendent essentiellement du système d'exploitation. Elles sont difficilement programmables sous DOS: un Pentium ou un vieux 80286 sont totalement similaires, de ce point de vue, alors que le premier est un processeur très sophistiqué.