![]()
![]()
![]() Chapitre 3
Chapitre 3
Relations entre processus
III-2.1. Classes de processus
Rappelons tout d'abord qu'un processus est un programme en cours d'exécution dans la mémoire. Il est décrit par son contexte.
|
|
|
Exécution successive de P et Q |
Deux processus peuvent posséder des contextes disjoints ou communs. Ainsi ils peuvent employer le même segment de code. C'est le cas dans une machine multi-utilisateurs lorsque plusieurs personnes utilisent simultanément un éditeur de texte. Une seule copie du segment programme réside en mémoire, chaque processus possède sa propre version du segment de données et son propre contexte. Il serait inutile de dupliquer le segment code puisqu'il est identique. Un thread est un sous-processus, en ce sens qu'il ne possède pas de contexte disjoint du processus à partir duquel il a été démarré. Il exécute cependant une partie de code qui lui est propre au moyen d'un mécanisme qui sera décrit plus loin, en ce qui concerne Unix.
Une machine monoprocesseur ne peut effectuer qu'un seul calcul à la fois et ne travaille donc, à un instant donné, que pour un seul processus. La simultanéité vraie n'existe donc pas. Nous considérerons, pour le moment, que cela veut simplement dire que le processeur s'intéresse tour à tour à chaque processus. Seul un ordinateur qui possède plusieurs processeurs (machines multiprocesseurs et machines massivement parallèles) permet une simultanéité complète. Cependant, nous verrons qu'on peut en donner l'apparence, avec un monoprocesseur, car lécoulement du temps, à l'échelle d'un être humain, est infiniment grande par rapport à la rapidité d'un processeur. Comme au cinéma où la continuité du mouvement est une illusion obtenue au moyen d'un cadencement d'images fixes, le processeur peut nous donner l'apparence de la simultanéité en alternant rapidement les taches auxquelles il s'intéresse.
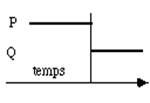
On peut envisager trois méthodes pour exécuter deux processus P et Q. Dans le premier cas on exécute P entièrement puis on charge le contexte de Q et on l'exécute à son tour (fig. 3.1). Cette méthode est simple mais frustrante pour Q qui peut attendre longtemps! Il n'y a pas apparence de simultanéité. Nous ne nous y intéresserons donc pas.
Une autre technique est l'alternat : on exécute alternativement une série d'instructions de l'un puis de l'autre processus. Ils sont arrêtés en des points interruptibles ou observables. A chaque fois on sauvegarde le contexte du processus interrompu et on charge celui du processus à exécuter (fig. 3.2).
|
|
| figure 3.2 : Exécution alternée de P et Q |
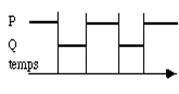
Lorsqu'on abuse de ce mécanisme, le système d'exploitation peut passer un temps non négligeable dans ces opérations de changement de contexte et donc perdre son efficacité. Chaque processus s'écoule harmonieusement ; cependant lorsque le processus actif est interrompu par une entrées-sortie, il faut prévoir un mécanisme pour démarrer immédiatement l'autre processus.
|
|
| figure 3.3 : Exécution parallèle de P et Q |

Enfin, la dernière méthode nécessite autant de processeurs que de processus (fig. 3.3). Chaque processus s'exécute sur un processeur distinct. C'est le seul cas de vrai parallélisme. Cependant si les processus P et Q concourent à la même tâche et doivent échanger des informations, on retrouvera une problématique commune aux deux autres cas car il sera nécessaire de les synchroniser. Les difficultés dans la mise au point des algorithmes parallèles tiennent essentiellement à la gestion de ces points de synchronisation et aux échanges entre processeurs. Ce problème est très étudié actuellement avec l'apparition des machines massivement parallèles. Les compilateurs parallélisant comme HPF (Highly Parallel Fortran) n'y réussissent que très partiellement.
Il est important de bien définir le niveau d'observation du parallélisme. Si celui-ci est le temps d'exécution total des processus, c'est à dire si le temps entre chaque observation est supérieur à la durée de vie moyenne d'un processus, alors dans tous les cas, y compris celui qui correspond au schéma de la figure 3.1, P et Q devront être considérés comme parallèles. Il en est de même pour le temps partagé: l'impression de parallélisme ressentie par chaque usager provient du fait que le temps d'exécution alloué à chaque processus est très court par rapport aux capacités d'observation d'un opérateur humain. Le moniteur alloue à chacun des tranches de temps 19-Sep-2008p faibles pour qu'un homme puisse être sensible à l'échantillonnage réalisé par l'ordinateur.
III-2.2. Compétition entre processus
Lorsque plusieurs processus doivent accéder à un objet commun, celui-ci constitue une ressource critique. Ils sont dits en exclusion mutuelle pour cette ressource lorsqu'ils doivent en prendre l'usage de façon exclusive. L'exemple le plus évident est l'usage du processeur mais cela se produit également dans bien d'autres cas, par exemple lors d'entrées-sorties pour accéder 19-Sep-2008alement se trouver en exclusion mutuelle pour une ressource interne commune : imaginons un mécanisme de transfert où un premier processus écrit dans un tampon qu'un deuxième lit. Ils ne doivent pas y accéder simultanément : cette ressource est donc critique. Les parties de code qui correspondent à l'accès au tampon sont dites des zones critiques et doivent être étudiées avec soin pour éviter tout problème. Il faut gérer les problèmes de synchronisation qui sont schématisés dans la figure 3.4. Dans ce schéma un premier processus P écrit dans le tampon. Q le lit. Les symboles S enfermés dans un cercle indiquent les points de synchronisation nécessaires et le sens de celle-ci.
La synchronisation revient à imposer des contraintes aux deux processus :
- précédence des processus : Q ne peut lire que si P a écrit.
- conditions de franchissement de certains points critiques : P ne peut écrire que si Q a terminé le transfert.
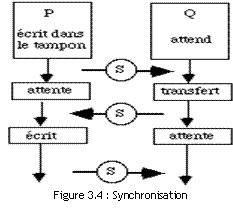 On voit apparaître, à travers cet exemple simple, les conditions indispensables pour réaliser une synchronisation :
On voit apparaître, à travers cet exemple simple, les conditions indispensables pour réaliser une synchronisation :
- les processus doivent échanger des informations.
- le processus synchronisable est celui qui reçoit l'information
- la synchronisation est un mécanisme bloquant : ne pourra être synchronisé qu'un processus qui attendra l'arrivée de l'information que doit lui transmettre le processus qui le synchronise.
On dit d'un processus qu'il est en attente ou bloqué s'il attend une ressource non disponible.
Il faut donc définir les transitions:
-actif
-bloqué pour arrêter l'exécution
-bloqué
-actif pour reprendre l'exécution.
On parle aussi de réveil du processus.
Les points où les processus subissent des transitions s'appellent des points de synchronisation. Nous décrirons dans la section III.3 différentes méthodes de synchronisation mais dés à présent nous pouvons en exposer la problématique au moyen d'un exemple simple : cela peut être la source de bien des blocages dans un système.
Synchroniser deux processus se résume donc à l'ensemble des règles ci-dessous:
| q On synchronise le processus rapide sur le processus lent. Il faut donc évaluer leur vitesse relative : si P est beaucoup plus rapide que Q, seul P doit être synchronisé. La nécessité d'une synchronisation bidirectionnelle ne se fera ressentir que dans le cas où on ne peut estimer ces vitesses relatives. |
| q Le processus synchronisé reçoit un signal, le processus synchronisant émet ce signal. |
| q Un processus n'est synchronisable qu'en un point où il est interruptible. |
Reprenons maintenant l'exemple de la figure 3.4 et traduisons l'enchaînement des opérations dans un pseudo-langage proche du langage C. Nous introduisons une variable d'état e qui vaut :
-0 si l'événement a eu lieu
-1 dans le cas contraire.
Les codes des processus P et Q sont :
| processus P |
processus Q |
| e = 1; |
f = 0; |
| if ( f == 1) { |
{ if ( e== 1) { |
| attendre; } |
attendre; } |
| while (éléments à calculer) |
f = 1; |
| { calculs des éléments à transférer |
lire tampon (a); |
| écrire tampon (a); |
f = 0; |
| e = 0; } |
Dans ce code très simplifié les variables e et f permettent de synchroniser les processus et d'éviter que P ne réécrive dans le tampon avant que Q n'ait terminé le transfert. De même Q se met en attente si le tampon n'est pas encore rempli. On ne fait aucune hypothèse sur les vitesses relatives des deux processus.
On est cependant loin d'un code complet. Rien n'est dit sur la fonction attendre, sur la façon de tester s'il y a des calculs à effectuer ou des éléments à transférer. Rien non plus sur la manière dont les deux processus P et Q peuvent partager les variables e et f ni sur le moment où ils ont démarré.
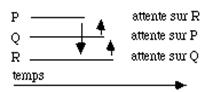
Imaginons maintenant le cas de trois processus P, Q, R qui concourent au même travail. P doit attendre que R ait fait sa part pour continuer, Q doit faire de même vis à vis de P et R vis à vis de Q. On utilise trois variables d'état e, f et g. Cela donne les éléments de code suivants :
| pocessus P |
processus Q |
processus R |
| e = 1; |
f = 1; |
g = 1; |
| if ( g ==1) |
if (e ==1) |
f ( f== 1) |
| travail à effectuer; |
travail à effectuer; |
travail à effectuer; |
| e = 0; |
f = 0; |
g = 0; |
Les trois processus vont se mettre en attente les uns sur les autres. On parle alors de verrou mortel ou dead lock (fig. 3.5)..
|
|
Cet exemple est caricatural parce que particulièrement simple à détecter. Mais lorsqu'il existe un grand nombre de processus asynchrones qui peuvent entrer à tout instant en compétition pour une ressource, le problème peut demeurer invisible tant que la machine n'est pas trop sollicitée. |
| figure3.5 : Exemple de verrou mortel |
Il n'est pas possible de prévoir le moment exact où un événement se produit, on ne connaît que les temps logiques, c'est à dire l'ordonnancement des instructions à l'intérieur des processus séparément. On ne peut donc pas être certain qu'une instruction d'un premier processus se déroulera toujours avant une instruction repérée dans un deuxième si on n'a pas prévu de mécanismes d'échanges suffisants pour les synchroniser. L'ordonnancement peut se trouver inversé en cas de forte charge du processus lorsque de nouveaux processus sont actifs à leur tour et ceci peut déclencher un blocage. Ceci est bien connu des concepteurs de systèmes qui savent que des arrêts et des erreurs peuvent se produire lors des premières utilisations en vraie grandeur des logiciels qu'ils développent. C'est une des nombreuses raisons pour lesquelles il faut toujours prévoir des périodes d'essai et de montée en charge progressive.
Un autre exemple de dysfonctionnement sera évoqué dans la section 3.3 : le système ne se bloque jamais mais en fonction du taux d'utilisation de la machine et de la vitesse relative des processus les résultats sont justes ou faux !
Précisons maintenant la notion de temps logique. L'exécution du processus P peut être décrite comme la succession des instructions de son programme. Les notions de précédence et de successeur sont donc parfaitement définies à l'intérieur du processus. Néanmoins celui-ci peut être interrompu en chaque point interruptible, c'est à dire entre chaque instruction. Ces deux notions n'ont donc plus aucune signification, au niveau du système d'exploitation qui gère plusieurs processus asynchrones. L'ordre exact des instructions de l'ensemble des processus ne peut pas être prévu à l'avance. La connaissance des temps logiques des processus ne permet pas de construire le chronogramme, c'est à dire le diagramme, en fonction du temps, de la suite des instructions exécutées successivement par le processeur. L'activation des points de synchronisation se produit de manière aléatoire.
Lorsque des processus sont synchrones l'état de chacun est, à chaque instruction, parfaitement défini par rapport aux autres. Le travail coopératif est donc beaucoup plus simple à organiser.
III-3. Mécanismes de synchronisation
Nous allons évoquer dans ce paragraphe les techniques les plus classiques employées pour réaliser les mécanismes de synchronisation que nous nous étions limités à évoquer sous la forme de variables partagées.
III-3.1. Synchronisation par moniteur
Le moniteur est le cur du système d'exploitation. Il est constitué d'un ensemble de procédures et de variables d'état utilisées par ces procédures. Certaines de ces variables sont accessibles à l'utilisateur grâce à des bibliothèques de fonctions spéciales. Ce sont les points d'entrée du moniteur. Les procédures externes au moniteur peuvent interroger et utiliser ces variables mais elles ne peuvent pas les modifier car il est fort probable que cela perturberait le fonctionnement du moniteur donc de l'ordinateur.
Parmi ces fonctions il en existe qui permettent de bloquer ou de réveiller les processus écrits par les utilisateurs. Le blocage et le réveil s'effectuent au moyen d'une condition c utilisable dans les trois opérations suivantes:
| q attendre(c): bloque le processus p qui l'utilise et le place en attente de l'événement c. |
| q vide(c) retourne vrai si il n'existe pas de processus en attente de c, faux sinon. |
| q activer(c) réveille le premier processus en attente de l'événement c. |
On notera que la fonction attendre(c) suppose l'existence d'une file d'attente associée. Ce concept sera évoqué dans la section V.2. Le processus réveillé reprend son activité à l'instruction qui suit le point d'arrêt.
Insistons sur une caractéristique essentielle de la synchronisation par moniteur : les processus consultent l'état de variables qu'ils ne peuvent modifier en aucun cas. C'est donc un moyen assez frustre car les communications sont réduites au minimum mais simple à réaliser.
III-3.2. Sémaphores
La synchronisation par sémaphore ou flag est un moyen simple et ancien de synchroniser des processus parallèles. Le principe est directement hérité des chemins de fer d'où son nom : lorsque le sémaphore est levé, le processus P peut continuer son chemin; lorsqu'il est baissé il doit attendre jusqu'à ce qu'un autre processus Q le lève. P et Q sont l'équivalent de deux trains roulant sur deux voies distinctes qui doivent se synchroniser pour pouvoir franchir un croisement sans accident.
Dans le modèle le plus simple il existe trois primitives:
|
|
|
Les sémaphores sont des variables communes mises à la disposition des différents processus par le système d'exploitation qui peuvent les consulter, les modifier et sur lesquelles ils peuvent se mettre en attente.
Reprenons l'exemple du transfert de résultats au moyen d'un tampon, que nous avons décrit au paragraphe 2.2. Le fonctionnement est le suivant:
| Processus P |
Processus Q |
| baisser(e); |
lever(f); |
| while (calculs à faire){ |
while (éléments à transférer) { |
| calculs des éléments du tampon (a); |
if (flag(e)) { |
| baisser(e); |
attendre(e) |
| if (flag(f)) { |
} |
| attendre(f); |
baisser(f); |
| } |
lire tampon(a); |
| écrire tampon (a); |
lever(f); |
| lever(e); |
} |
| } |
Au paragraphe 2.2 nous n'avions pas évoqué comment les variables e et f pouvaient être communes à deux processus distincts. Les sémaphores sont un moyen de résoudre ce problème. Ils font partie du contexte commun à l'ensemble des processus. Ces variables ne peuvent prendre que deux valeurs. Elles doivent être déclarées au moyen d'instructions spéciales qui précisent les noms des processus qui peuvent les partager. Les sémaphores sont un moyen simple de synchronisation mais il est difficile, comme nous l'avons vu, de se prémunir complètement contre les risques d'inter blocage.
On peut sophistiquer le modèle du sémaphore en y associant des compteurs à valeurs entières associés à des files d'attente. Ceci permet de gérer plusieurs processus qui doivent se partager une ressource unique. Imaginons N processus Pi qui calculent et remplissent des tampons distincts, de la même façon que le processus P que nous venons d'étudier. Un seul processus Q est chargé du transfert des résultats sur le disque pour tous les processus P. Il ne peut traiter qu'un seul tampon à la fois. Il faut deux sémaphores pour synchroniser les processus Pi et Q. Il faudrait donc prévoir 2N sémaphores lors de la programmation du transfert. Ceci est rigide et ne permet pas facilement de changer le nombre de processus. Si on ajoute une file d'attente associée au sémaphore f il devient possible de gérer un nombre indéterminé de processus avec ce sémaphore unique. Imaginons par exemple un sémaphore s. On lui associe un compteur s.c et une file d'attente s.f. Un processus emploiera le sémaphore au moyen de deux procédures:
-stop(s) qui arrête éventuellement le processus.
-start(s) qui active éventuellement le processus.
Lorsque la valeur du sémaphore est négative tous les processus inscrits dans sa file d'attente sont bloqués.
Schématiquement le fonctionnement de ces procédures est le suivant :
| stop(s) |
start(s) |
| { |
{ |
| s.c = s.c - 1; |
s.c = s.c + 1; |
| if (s.c < 0) { |
if (s.c >= 0) { |
| attendre(); |
sortir(s.f); |
| activer(); | |
| } |
} |
| } |
} |
attendre() et activer() mettent le processus en attente ou le réactive, entrer(s.f) et sortir(s.f) sont deux fonctions qui incluent et extraient le processus de la file d'attente f associée au sémaphore s. On remarquera que si stop(s) peut bloquer le processus qui l'utilise. start(s) n'est jamais bloquante.
III-3.3. Dysfonctionnement de la synchronisation
Evoquons maintenant un problème grave de dysfonctionnement du à une mauvaise utilisation des sémaphores. En apparence tout fonctionne mais suivant la charge de la machine et la vitesse relative des processus, les résultats sont justes ou faux. Pour l'illustrer reprenons le cas étudié précédemment de deux processus P et Q qui collaborent à une opération d'écriture. P écrit alternativement dans deux tampons pendant que Q les lit et les transfert. Nous n'avions auparavant envisagé l'existence que d'un seul tampon. Un fonctionnement possible des processus est illustré dans le diagramme de la figure 3.6.
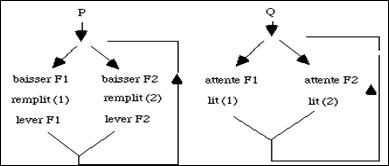
figure 3.6 - Fonctionnement coopératif de deux processus
Un dispositif de multiplexage, qui n'est pas expliqué dans la figure, engage P ou Q à utiliser alternativement les branches de gauche et de droite et à remplir les tampons (1) ou (2) successivement. P est protégé pendant son travail au moyen des sémaphores, F1 ou F2 selon le tampon qu'il remplit. Lorsqu'un tampon est plein le sémaphore correspondant est levé et ceci permet au processus Q de le lire et de le transférer. On n'envisage pas la méthode d'arrêt des processus.
Ce diagramme suppose une bonne connaissance de l'avancement relatif des deux processus. Si P est plus lent que Q, ce schéma est à priori correct puisque rien n'est prévu pour synchroniser P sur Q. Mais si P est beaucoup plus lent que Q, on peut se trouver devant un fonctionnement complètement incohérent. En sortie de branche 2, les deux sémaphores sont levés. Si le temps nécessaire pour passer de "lever F2" à "baisser F1", dans P, est plus grand que le temps de lecture du tampon (2) et de relecture du tampon (1), le sémaphore F1 bascule trop tard alors que Q a déjà lu le tampon (1) pour la deuxième fois! Il suffit donc que la vitesse de P, relativement à celle de Q, soit modifiée, pour basculer d'un fonctionnement correct à un fonctionnement faux. P doit être protégé pendant qu'il remplit l'un des tampons contre toute lecture prématurée de la part de Q. Or ceci peut se produire sans aucun avertissement simplement en modifiant les conditions de fonctionnement de l'ordinateur, par exemple en démarrant de nouveaux processus étrangers à cette tâche. L'erreur est difficile à analyser puisqu'elle se produit de façon aléatoire. Ce genre de problème est fréquent dans les systèmes temps réel lorsque les hypothèses sur les vitesses relatives des processus sont mal fondées et ont amenés à ne pas se soucier de synchronisation dans les deux sens, c'est à dire de P sur Q et de Q sur P.
Le démarrage des systèmes Unix en fournit un bon exemple. Le premier processus créé démarre successivement de nombreux autres processus. Leur ordre de départ n'est pas indifférent, certains doivent être actifs ou avoir terminé leur travail pour que ceux, lancés après eux, puissent démarrer correctement. Or, lorsqu'on augmente le nombre de fonctionnalités d'une machine, il faut également accroître le nombre de processus qui sont initialisés au démarrage. Dans les systèmes les plus anciens de nombreux points de synchronisation avaient été oubliés dans la procédure de début. La puissance du processeur devenait insuffisante pour démarrer à temps tous les processus nécessaires au fonctionnement de la configuration désirée. Les premiers processus étaient ralentis par le démarrage des suivants et n'avaient pas terminé leur phase d'initialisation à temps. Ces derniers processus ne se trouvaient donc plus dans la configuration désirée, au moment de leur lancement, et soit s'arrêtaient sur erreur soit fonctionnaient mal. Du fait de l'asynchronisme de tous ces processus, il se pouvait même que d'un démarrage sur l'autre, le comportement de la machine soit différent! Cela ne provenait pas vraiment d'une erreur des concepteurs car ils n'avaient pas imaginé qu'on puisse demander tant à ces ordinateurs. Depuis des points de synchronisation ont été introduits dans la procédure de démarrage pour éviter ce problème.
Lorsqu'on estime le temps de travail d'un processus il faut non seulement évaluer le temps logique (temps total d'enchaînement des instructions) mais aussi le temps réel en tenant compte des inférences avec les autres processus. Si les processus P et Q s'exécutent avec le même niveau de priorité il est possible que le processeur entrelace leurs instructions. Ceci permet alors de prévoir assez bien la cohérence de leur fonctionnement . C'est ce qu'on fait inconsciemment lorsqu'on cherche à synchroniser deux processus. Mais si ceux-ci fonctionnent à des vitesses différentes il est souvent bien difficile d'estimer précisément ces vitesses relatives. Il est donc très dangereux de vouloir synchroniser deux processus ou plus sans utiliser les outils adéquats. L'exemple suivant le montre amplement.
Deux processus P et Q exécutent la même série d'instructions :
| Processus P |
Processus Q |
| n = 0; |
n = 0; |
| .... |
.... |
| n = n + 1; |
n = n + 1; |
| if ( n < 2){ |
if ( n < 2){ |
| attendre; |
attendre; |
| } else { |
} else { |
| continuer... |
continuer... |
| } |
} |
Imaginons que Q démarre immédiatement après P. Il va devenir prioritaire car P change la valeur de la variable n de 0 en 1 et se met en attente. Q ajoute à son tour 1 à cette même variable qui vaut maintenant 2 et dépasse P. La tortue a dépassé le lièvre!
Imaginons maintenant la séquence suivante d'instructions générée en assembleur (la colonne de droite contient les explications sur le pseudo-code assembleur):
load Ri, n charger n dans le registre Ri
add Ri,1 addition immédiate de 1 à Ri
put Ri, n place Ri dans la mémoire n
III-4.3 Les threads
Un processus définit lensemble des ressources nécessaires à lexécution dun programme. Plusieurs processus peuvent, comme nous lexpliquerons plus en détails au chapitre V, exécuter le même code mais ils disposent chacun dun espace dadressage et dautres ressources propres nécessaires à leur exécution.
Lapparition des machines multiprocesseurs, le développement dapplications client-serveur dans lesquelles une machine doit répondre à de nombreuses requêtes, ont montré les limites de ce modèle. La création dun processus est couteuse. Elle mobilise de nombreuses ressources car il est nécessaire de créer tout son environnement.
Il est difficile de faire exécuter le code dun processus sur plusieurs processeurs simultanément : cela signifie quil faut pouvoir le paralléliser automatiquement à un niveau très fin et cela est difficilement envisageable. On a donc imaginé la possibilité de découper un processus en sous processus ou threads. Tous les threads partagent le même environnement que le processus dont ils sont issus et exécutent chacun la tache pour laquelle ils ont été programmés. On peut donc facilement imaginer quils puissent être exécutés sur des processeurs différents. On obtient ainsi un certain degré de parallélisme qui est très efficace. Le programmeur a déterminé, lors de l'écriture du code les parties qui pouvaient sexécuter simultanément et les a groupées dans ces sous unités.
On peut schématiser le partage des ressources entre processus et threads comme indiqué sur la figure yyy.
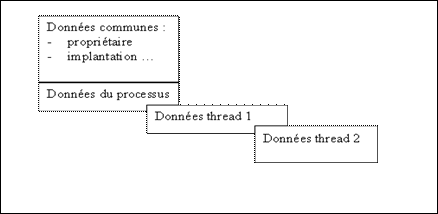
figure 3.15 : schéma du partage des ressources entre un processus et ses threads
Parmi les données communes au processus et aux threads, on peut citer :
|
|
|
|
Le processus comme chaque thread possède en propre :
|
|
|
|
Même dans le cas de machines monoprocesseurs les threads se révèlent utiles. Créer un processus est très onéreux. Lorsquun serveur doit répondre à de nombreuses requêtes un temps précieux est donc perdu à créer un processus pour répondre à chacune dentre elles. Les threads sont beaucoup plus économiques puisquils partagent un environnement unique qui ne doit donc pas être initialisé pour chacun dentre eux.
Cest pourquoi les systèmes Unix les plus récents ont ajouté cette fonctionnalité.