Programmation en assembleur
I ) Introduction :
Lorsque l'on doit lire ou écrire un programme en langage machine, il est difficile d'utiliser la notation hexadécimale. On écrit les programmes à l'aide des instructions en mnémonique comme MOV, ADD, etc. Les concepteurs de processeurs, comme Intel, fournissent toujours une documentation avec les codes des instructions de leurs processeurs, et les symboles correspondantes.
L'assembleur est un utilitaire qui n'est pas interactif, (contrairement à l'utilitaire comme debug : voir plus loin dans le cours). Le programme que l'on désire traduire en langage machine (on dit assembler) doit être placé dans un fichier texte (avec l'extension .ASM sous DOS).
La saisie du programme source au clavier nécessite un programme appelé éditeur de texte.
L'opération d'assemblage traduit chaque instruction du programme source en une instruction machine. Le résultat de l'assemblage est enregistré dans un fichier avec l'extension .OBJ (fichier objet).
Le fichier .OBJ n'est pas directement exécutable. En effet, il arrive fréquemment que l'on construise un programme exécutable à partir de plusieurs fichiers sources. Il faut (relier) les fichiers objets à l'aide d'un utilitaire nommé éditeur de lien (même si l'on a qu'un seul). L'éditeur de liens fabrique un fichier exécutable, avec l'extension .EXE.
Le fichier .EXE est directement exécutable. Un utilitaire spécial du système d'exploitation (DOS ici), le chargeur est responsable de la lecture du fichier exécutable, de son implantation en mémoire principale, puis du lancement du programme.
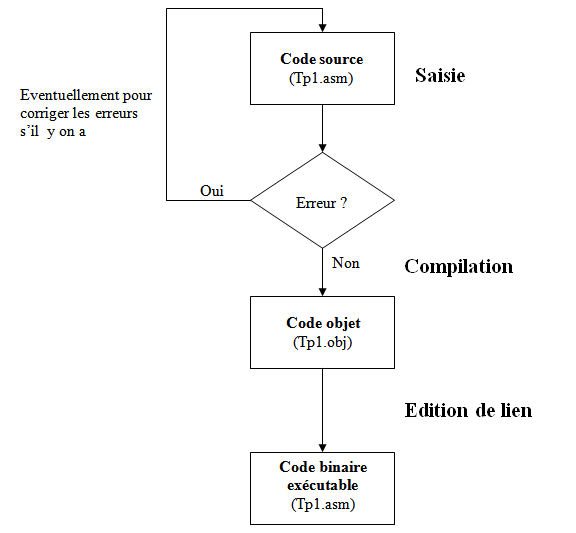
Donc en conclusion pour assembler un programme on doit passer par les phases suivantes :
- Saisie du code source avec un éditeur de texte.
- Compiler le programme avec un compilateur.
- Editer les liens pour avoir un programme exécutable. Les trois phases sont schématisées par la figure suivante :
Remarque 1 :
- On ne peut passer du code source vers le code objet que si le programme source ne présente aucune erreur.
- La saisie se fait par des logiciels qui s'appellent éditeurs de texte, donc on peut utiliser n'importe quel éditeur de textes (tel que EDLINE sous MSDOS de Microsoft) sauf les éditeurs sous Windows car ces éditeurs ajoutent dans le fichier des informations (la taille des caractères, la police utilisée, la couleur etc...) que l'assembleur ne peut pas comprendre .Pour utiliser les éditeurs sous Windows il est conseiller d'enregistrer les fichiers sous forme RTF.
Editeur de lien :
- permet de lier plusieurs codes objets en un seul exécutable.
- permet d'inclure des fonctions prédéfinies dans des bibliothèques.
Plusieurs logiciels permettent le passage entre les trois phases présentée dans la figure précédente on peut citer : MASM (Microsoft Assembler : avec LINK comme éditeur de lien), TASM (Turbo assembler : avec TLINK comme éditeur de lien) et NASM etc ...
Remarque 2 :
On peut générer à partir d'un fichier objet d'autres formes de fichier pour des systèmes autres que l'ordinateur (compatible IBM). Les formes les plus connues sont INTEL HEX, ASCII HEX etc ...
Remarque 3 :
L'assembleur est utilisé pour être plus prés de la machine, pour savoir exactement les instructions générées (pour contrôler ou optimiser une opération) On retrouve l'assembleur dans :
- la programmation des systèmes de base des machines (le pilotage du clavier, de l'écran, etc...),
- certaines parties du système d'exploitation,
- le pilotage de nouveaux périphériques (imprimantes, scanners, etc..
- l'accès aux ressources du système,
L'avantage donc de l'assembleur est de générer des programmes efficaces et rapides (à l'exécution) par contre ses inconvénients : développement et mise au point long.
II ) Le fichier source (code source) :
Comme tout programme, un programme écrit en assembleur (programme source) comprend des définitions, des données et des instructions, qui s'écrivent chacune sur une ligne de texte.
Les données sont déclarées par des directives, mots clefs spéciaux que comprend l'assembleur (donc ils sont destinés à l'assembleur. Les instructions (sont destinées au microprocesseur)
II-1 ) Les instructions :
La syntaxe des instruction est comme suit :
{Label :} Mnémonique {opérande} { ; commentaire}
- Le champ opérande est un champ optionnel selon l'instruction (parfois l'instruction nécessite une opérande et parfois non).
- Le champ commentaire : champ sans signification syntaxique et sémantique pour l'assembleur , il est optionnel mais très intéressant lorsque on programme en assembleur, en effet les instructions en assembleur sont des instructions élémentaires donc dans un programme le nombre d'instructions et assez élevé (par exemple pour utiliser des fonctions tels que COS ou SIN il faut réaliser ça en utilisant des opérations arithmétiques et logiques de base) donc contrairement au langage évolué de programmation dans les programmes source on va trouver plus d'instructions. Ce qui va rendre la compréhension des programmes assez délicate et difficile. Pour cette raison lorsque on programme en assembleur il vaut mieux mettre des commentaires pour que le programme soit lisible pour les utilisateurs.
Remarque :
Les commentaires sont mis en général dans les passages délicats.
- Le champ Label (étiquette) est destiné pour marquer une ligne qui sera la cible d'une instruction de saut ou de branchement. Une label peut être formée par 31 caractère alphanumérique ({A.. Z} {a.. z} {0.. 9} {.?@_$}) au maximum .Les noms des registres ainsi que la représentation mnémonique des instructions et les directives (voir plus loin) ne peuvent être utilisées comme Label. Le champ Label doit se terminer par ' : ' et ne peut commencer par un chiffre. De même il n'y a pas de distinction entre minuscules et majuscules.
Exemple :
ET1 : MOV AX , 500H ; mettre la valeur 500 dans le registre AX
II-2 ) Les directives :
Pour programmer en assembleur, on doit utiliser, en plus des instructions assembleur, des directives ou pseudo-instructions : Une directive est une information que le programmeur fournit au compilateur. Elle n'est pas transformée en une instruction en langage machine. Elle n'ajoute donc aucun octet au programme compilé. Donc les directives sont des déclarations qui vont guider l'assembleur.
Une directive est utilisée par exemple pour créer de l'espace mémoire pour des variables, pour définir des constantes, etc...
Pour déclarer une directive il faut utiliser la syntaxe suivante :
{Nom} Directive {opérande} { ; commentaire}
- Le champ opérande dépend de la directive
- Le champ commentaire a les mêmes propriétés vues dans le paragraphe précèdent.
- Le champ Nom indique le nom des variables : c'est un champ optionnel (selon la directive).
II-3 /Exemple de directives :
III- 3-1 ) Les directives de données :
III-3- 1-1 / EQU :
Syntaxe : Nom EQU Expression
Exemples :
VAL EQU 50 ; assigne la valeur 50 au nom VALET1 EQU VAL* 5 + 1 ; assigne une expression calculer a VALIII-3- 1-2 ) DB/DW/DD/DF/DP/DQ/DT:
Ces directives sont utilisées pour déclarer les variables : L'assembleur attribue à chaque variable une adresse. Dans le programme, on repère les variables grâce à leurs noms. Les noms des variables sont composés d'une suite de 31 caractères au maximum, commençant obligatoirement par une lettre. Le nom peut comporter des majuscules, des minuscules, des chiffres, plus les caractères @, et _. Lors de la déclaration d'une variable, on peut lui affecter une valeur initiale.
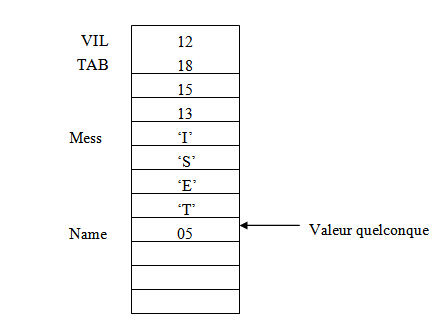
a° ) DB (Define byte): définit une variable de 8 bits : c a d elle réserve un espace mémoire d'un octet : donc les valeurs qu'on peut stocker pour cette directive sont comprises entre 0 et 255 ( pour les nombres non signés ) et de -128 jusqu'à 127 pour les nombres signés .
Syntaxe : Nom DB Expression
Exemple :
Vil DB 12H ; Définit une variable (un octet) de valeur Initiale 12.Tab DB 18H, 15H, 13H ; définit un tableau de 3 cases ;(3 octet) Qui démarre à partir de l'adresse TAB.Mess DB 'ISET' ; définit aussi un tableau mais les valeurs de chaque case ;n'est autre que le code ascii de chaque lettre.Name DB ? ; définit une variable 8 bits de valeur initiale quelconque .
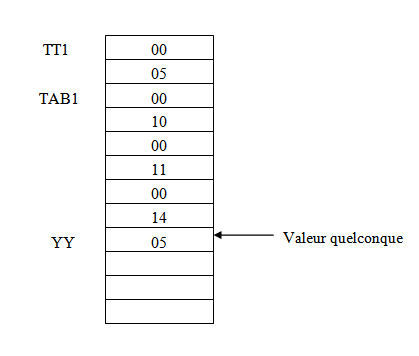
b° ) DW ( define word) : définit une variable de 16 bits : c a d elle réserve un espace mémoire d'un mot : donc les valeurs qu'on peut stocker pour cette directive sont comprises entre 0 et 65535 ( pour les nombres non signés ) et de -32768 jusqu'à 32767 pour les nombres signés .
Syntaxe : Nom DW Expression
Exemple :
TT1 DW 500H ; réserve deux cases mémoire (un mot) a partir de l'adresse TT1.TAB1 DW 10H,11H,14H ; réserve u tableau de 6 cases chaque valeur sera mise sur deux casesYY DW ? ; réserve un mot dans la mémoire de valeur initial quelconque.
c° ) DD : (Define Double) : réserve un espace mémoire de 32 bits ( 4 cases mémoire ou 4 octets ) :
Syntaxe : nom DD expression
Exemple :
ff DD 15500000He°/ Directive dup
Lorsque l'on veut déclarer un tableau de n cases, toutes initialisées à la même valeur, on utilise la directive dup:
tab DB 100 dup (15) ; 100 octets valant 15y DW 10 dup (?) ; 10 mots de 16 bits non initialisesf°/ Les direcitive Word PTR et Byte PTR :
Dans certains cas, l'adressage indirect est ambigu. Par exemple, si l'on
écrit :
MOV [BX], 0 ; range 0 a l'adresse spécifiée par BXL'assembleur ne sait pas si l'instruction concerne 1, 2 ou 4 octets
consécutifs. Afin de lever l'ambiguïté, on doit utiliser une directive spécifiant la taille de la donnée à transférer :
MOV byte ptr [BX], val ; concerne 1 octetMOV word ptr [BX], val ; concerne 1 mot de 2 octetsIII- 3-2 ) Les directives de segment :
La directive SEGMENT contrôle la relation entre la génération du code objet et la gestion des segments logiques ainsi générés.
L'instruction SEGMENT sert à :
- contrôler le placement du code objet dans des segments spécifiques.
- Associer les symboles représentant des adresses à un segment en considérant leur valeur comme un déplacement par rapport au début du segment.
- spécifier des directives pour l'editeur de lien (nom du segment, champs d'opérande de l'instruction SEGMENT déterminant le traitement du segment par l'éditeur de liens); ces informations sont passées telles quelles.
Syntaxe de la directive SEGMENT : Nom SEGMENT opérande
.
.
Nom ENDS
Le nom champ étiquette 'Nom' sert a :
- indiquer le nom du segment.
- établir une relation évidente entre des paires d'instructions
SEGMENT et ENDS. Alternance entre segments :
Un programme peut alterner entre différents segments pour y générer un code:
* L'instruction SEGMENT permet de re-ouvrir un segment déjà existant
(donc, SEGMENT soit crée un nouveau segment, soit ouvrir un segment en vue d'y ajouter du code supplémentaire).
Remarque :
Il ne faut pas oublier l'instruction ENDS avant une telle opération, elle permet de (temporairement) clore l'ancien segment.
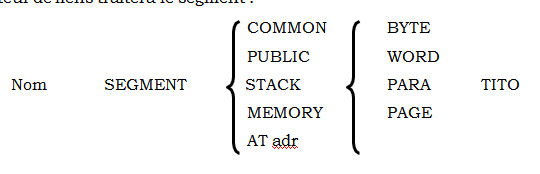
Les opérandes de l'instruction SEGMENT déterminent la manière dont l'éditeur de liens traitera le segment :
COMMON :
Tous les segments avec l'étiquette (classe) seront placés à la même adresse de base (dans un bloc contigu) ; des zones du type ( COMMON ) avec différents noms (( classe)) seront placés l'un derrière l'autre.
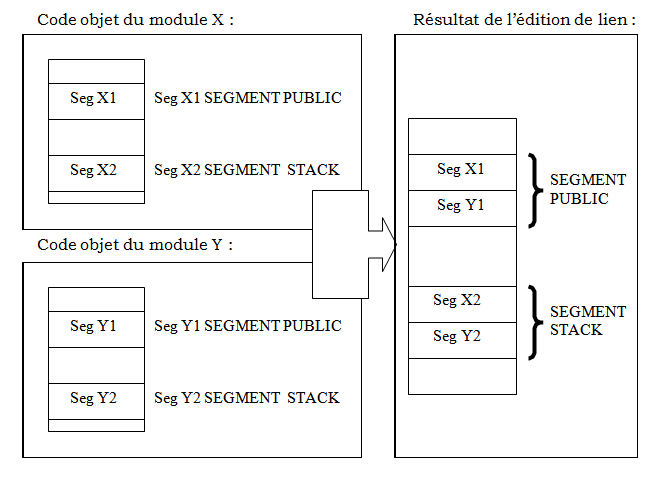
PUBLIC :
Tous les segments avec ce qualificatif seront regroupés dans un seul segment résultant, l'un derrière l'autre.
STACK :
Un seul segment avec ce qualificatif est accepté, il est destiné à la gestion de la pile.
MEMORY :
Le premier segment portant ce qualificatif sera placé à une position de mémoire en dessus de tout autre segment; s'il y a d'avantage de segments de ce genre, ils seront traités comme les segments du type ( COMMON ).
AT :
Les étiquettes définies dans un tel segment sont définies comme étant relatives à la valeur ((adr) ) 16) * 16.
e°/ Alignement de l'adresse de base d'un segment
Il est possible de contrôler la manière dont l'éditeur de liens détermine l'adresse ou sera placé un segment: on choisit l'alignement du segment (c.a.d de son premier byte).
IV ) Structure d'un programme source :
PROGRAM Exemple1Pile SEGMENT STACK ; On met les directives pour réserver de l'espace mémoire.PILE ENDSData SEGMENT ; On met les directives de données pour réserver de la mémoire ; Pour les variables qui seront utilisées dans le programme.Data ENDSExtra SEGMENT ; On met les directives pour déclarer ; ;les variables (les chaînes de Caractères).Extra ENDSCode SEGMENTASSUME cs : code, ds, data, es : pile :ss :pilePROGMov AX,DataMov DS,AXMov AX,ExtraMov ES,AXMov AX,pileMov SS,AX ; mettre les instructions du programmeCode ENDS END PROGComme tout programme, un programme écrit en assembleur comprend des définitions de données et des instructions, qui s'écrivent chacune sur une ligne de texte.
Les données sont déclarées par des directives, Les directives qui déclarent des données sont regroupées dans les segments de données, qui sont délimités par les directives SEGMENT et ENDS.
Les instructions sont placées dans un autre segment, le segment de code. La ligne :
Code SEGMENT
Sert à déclarer le segment code. On aurait aussi bien pu le nommer
(iset) ou (microprocesseur). Ce sera le segment de notre programme. Cette ligne ne sera pas compilée : elle ne sert qu'à indiquer au compilateur le début d'un segment.
La ligne :
PROG
La première instruction du programme (dans le segment d'instruction) doit toujours être repérée par une étiquette (dans notre cas : PROG). Le fichier doit se terminer par la directive END avec le nom de l'étiquette de la première instruction (ceci permet d'indiquer à l'éditeur de liens qu'elle est la première instruction à exécuter lorsque l'on lance le programme).
Comme nous l'avons vu, les directives SEGMENT et ENDS permettent de définir les segments de codes et de données. La directive ASSUME permet d'indiquer à l'assembleur quel est le segment de données et celui de codes
(etc...), afin qu'il génère des adresses correctes. Enfin, le programme doit commencer, avant toute référence au segment de données, par initialiser le registre segment DS (même chose pour : ES et SS), de la façon suivante :
MOV AX, DataMOV DS, AXRemarque:
On n'est pas tenu de rendre aux registres la valeur qu'ils avaient au début de notre programme. En effet, avant de charger un programme, le
DOS sauvegarde le contenu de tous les registres puis met le contenu des registres généraux (ainsi que SI, DI et BP) à zéro. Il les restaurera quand il prend la main.
V ) Structure d'un programme en mémoire :
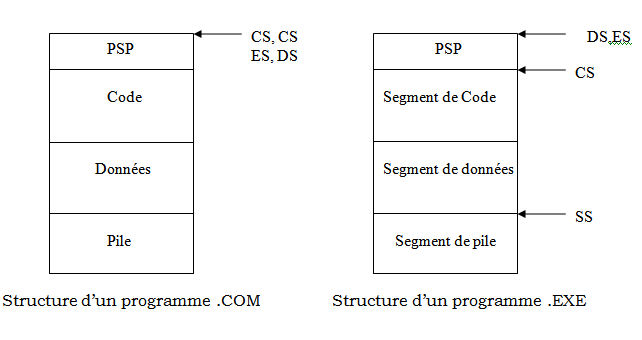
Lorsque l'utilisateur exécute un programme, celui-ci est d'abord chargé en mémoire par le système. Le DOS distingue deux modèles de programmes exécutables : les fichiers COM et les fichiers EXE.
La différence fondamentale est que les programmes COM ne peuvent pas utiliser plus d'un segment dans la mémoire. Leur taille est ainsi limitée à
64 Ko. Les programmes EXE ne sont quant à eux limités que par la mémoire disponible dans l'ordinateur.
a/ les fichiers COM :
Lorsqu'il charge un fichier COM, le DOS lui alloue toute la mémoire disponible. Si celle-ci est insuffisante, il le signale à l'utilisateur par un message et annule toute la procédure d'exécution. Dans le cas contraire, il crée le PSP du programme au début du bloc de mémoire réservé, et copie le programme à charger à la suite.
Le PSP (« Program Segment Prefix ») est une zone de 256 (100H) octets qui contient des informations diverses au sujet du programme. C'est dans le PSP que se trouve la ligne de commande tapée par l'utilisateur. Par exemple, le PSP d'un programme appelé MONPROG, exécuté avec la commande
(MONPROG monfic.txt /S /H), contiendra la chaîne de caractères suivante : ( monfic.txt /S /H). Le programmeur a ainsi la possibilité d'accéder aux paramètres.
Un programme COM ne peut comporter qu'un seul segment, bien que le DOS lui réserve la totalité de la mémoire disponible. Ceci a deux conséquences. La première est que les adresses de segment sont inutiles dans le programme : les offsets seuls permettent d'adresser n'importe quel
octet du segment. La seconde est que le PSP fait partie de ce segment, ce qui limite à 64 Ko-256 octets la taille maximale d'un fichier COM. Cela implique également que le programme lui-même débute à l'offset 100h et non à l'offset
0h.
b) les fichiers EXE :
Bien qu'il soit possible de n'utiliser qu'un seul segment à tout faire, la plupart des programmes EXE ont un segment réservé au code , un ou deux autres aux données, et un dernier à la pile.
Le PSP a lui aussi son propre segment. Le programme commence donc à l'offset 0h du segment de code et non à l'offset 100h.
Afin que le programme puisse être chargé et exécuté correctement, il faut que le système sache où commence et où s'arrête chacun de ces segments. A cet effet, les compilateurs créent un en-tête (ou « header ») au début de chaque fichier EXE. Ce header ne sera pas copié en mémoire. Son rôle est simplement d'indiquer au DOS (lors du chargement) la position relative de chaque segment dans le fichier.
Intéressons-nous à présent aux valeurs que le DOS donne à ces registres lors du chargement en mémoire d'un fichier exécutable ! Elles diffèrent selon que le fichier est un programme COM ou EXE. Pour écrire un programme en assembleur, il est nécessaire de connaître ce tableau par coeur :
Dans un fichier EXE, le header indique au DOS les adresses initiales de chaque segment par rapport au début du programme (puisque le compilateur n'a aucun moyen de connaître l'adresse à laquelle le programme sera chargé). Lors du chargement, le DOS ajoutera à ces valeurs l'adresse d'implantation pour obtenir ainsi les véritables adresses de segment.
Dans le cas d'un fichier COM, tout est plus simple. Le programme ne comporte qu'un seul segment, donc il suffit tout bêtement au DOS de charger CS, DS, ES et SS avec l'adresse d'implantation.
Remarque : Pourquoi DS et ES pointent-ils vers le PSP dans le cas d'un fichier
EXE ?
Première raison : pour que le programmeur puisse accéder au PSP ! Deuxième raison : parce qu'un programme EXE peut comporter un nombre quelconque de segments de données. C'est donc au programmeur d'initialiser ces registres, s'il veut accéder à ses données.
c°/ Structure d'un fichier .com
Code segmentAssume cs : code, ds : code, es : code, ss : code Org 100h ; le programme debut à partir de 100h Debut :.......... ; mettre les instructions..........Code endsEnd debutd°/ Structure d'un fichier .exe
Voir paragraphe IV /
Les directives de procédure :
Déclaration d'une procédure
L'assembleur possède quelques directives facilitant la déclaration de procédures. On déclare une procédure dans le segment d'instruction comme suit :
Calcul PROC near ; procedure nommé Calcul... ; instructionsRET ; dernière instructionCalcul ENDP ; fin de la procédureLe mot clef PROC commence la définition d'une procédure, near indiquant qu'il s'agit d'une procédure située dans le même segment d'instructions que le programme appelant.
L'appel s'écrit simplement : CALL Calcul
VI ) Les modes d'adressage du 8086:
Les instructions et leurs opérandes (paramètres) sont stockées en mémoire principale. La taille totale d'une instruction (nombre de bits nécessaires pour la représenter en mémoire) dépend du type d'instruction et aussi du type d'opérande. Chaque instruction est toujours codée sur un nombre entier d'octets, afin de faciliter son décodage par le processeur.
Une instruction est composée de deux champs :
- le code opération, qui indique au processeur quelle instruction réaliser.
- le champ opérande qui contient la donnée, ou la référence à une donnée en mémoire (son adresse).
Les façons de désigner les opérandes constituent les "modes d'adressage". Selon la manière dont l'opérande (la donnée) est spécifié, c'est à dire selon le mode d'adressage de la donnée, une instruction sera codée par 1, 2, 3 ou 4 octets.
Le microprocesseur 8086possède 7 modes d'adressage :
- Mode d'adressage registre.
- Mode d'adressage immédiat.
- Mode d'adressage direct.
- Mode d'adressage registre indirect.
- Mode d'adressage relatif à une base.
- Mode d'adressage direct indexe.
- Mode d'adressage indexée.
VI -1 ) Mode d'adressage registre :
Ce mode d'adressage concerne tout transfert ou toute opération, entre deux registres de même taille.
Dans ce mode l'opérande sera stockée dans un registre interne au microprocesseur.
Exemple :
Mov AX, BX ; cela signifie que l'opérande stocker dans le registre BX sera transféré vers le registre AX. Quand on utilise l'adressage registre, le microprocesseur effectue toutes les opérations d'une façon interne. Donc dans ce mode il n'y a pas d'échange avec la mémoire, ce qui augmente la vitesse de traitement de l'opérande.
IV -2 ) Mode d'adressage immédiat :
Dans ce mode d'adressage l'opérande apparaît dans l'instruction elle- même, exemple :
MOV AX,500H ; cela signifie que la valeur 500H sera stockée immédiatement dans le registre AX




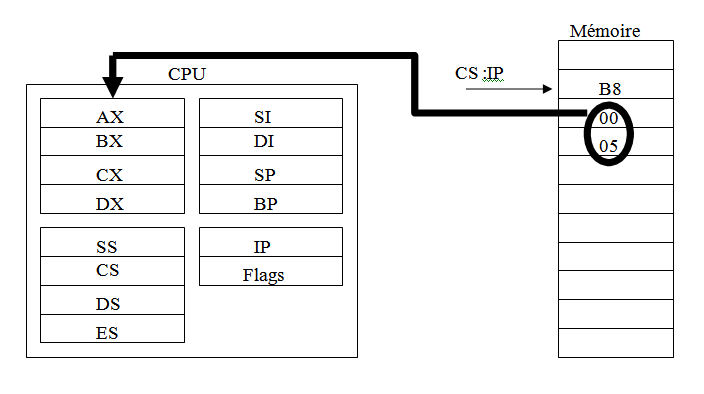
Remarque :
Pour les instructions telles que :
MOV AX,-500H ; le signe - sera propager dans ;le registre jusqu'à remplissage de ce dernier.Exemple dans notre cas MOV AX,-500H donne AX =1111101100000000B MOV BL,-20H donne BL = 11100000B
VI -3 ) Mode d'adressage direct :
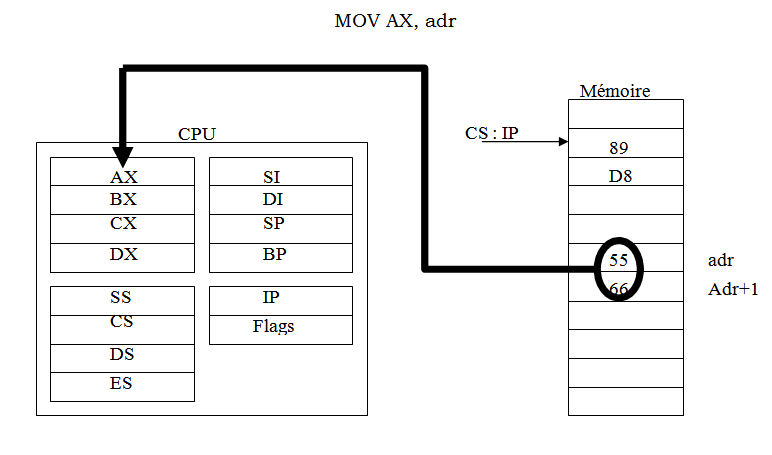
Dans ce mode on spécifie directement l'adresse de l'opérande dans l'instruction .exemple :
MOV AX,adrLa valeur adr est une constante (un déplacement) qui doit être ajouté au contenu du registre DS pour former l'adresse physique de 20 bits.
Remarque :
En général le déplacement est ajouté par défaut avec le registre segment DS pour former l'adresse physique de 20 bits, mais il faut signaler
qu'on peut utiliser ce mode d'adressage avec d'autres registres segment tel
que ES par exemple , seule la syntaxe en mnémonique de l'instruction change et devient :
MOV AX, ES : adrVI -4 ) Mode d'adressage registre indirect :
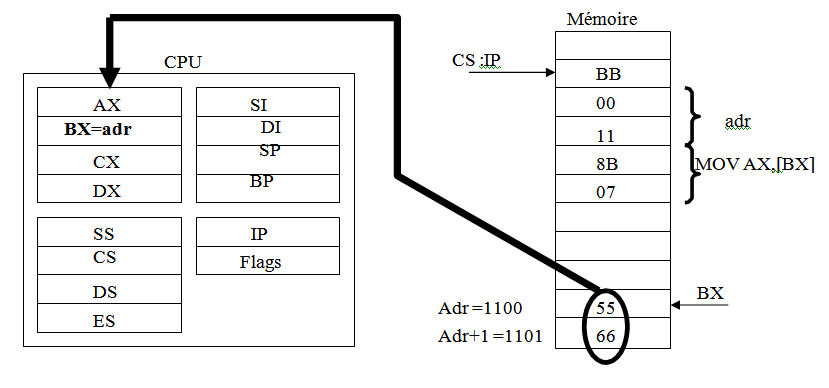
Dans ce mode d'adressage l'adresse de l'opérande est stockée dans un registre qu'il faut bien évidemment le charger au préalable par la bonne adresse. L'adresse de l'opérande sera stockée dans un registre de base (BX ou BP) ou un indexe (SI ou DI).
Exemple :
MOV BX,offset adrMOV AX,[BX]Le contenu de la case mémoire dont l'adresse se trouve dans le registre BX (c.a.d : Adr) est mis dans le registre AX
Remarque:
Le symbole [ ] design l'adressage indirect.
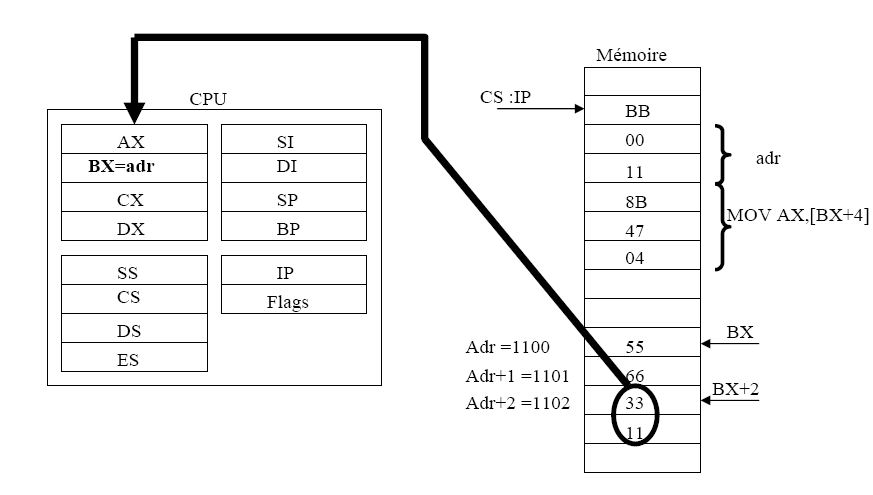
VI - 5 ) Mode d'adressage relatif à une base :
Dans ce mode d'adressage Le déplacement est déterminé par soi, le contenu de BX, soit le contenu de BP, auquel est éventuellement ajouté un décalage sur 8 ou 16 bits signé. DS et SS sont pris par défaut.
Exemple :
MOV AX,[BX]+2Cela signifie que dans le registre AX on va mettre le contenu de la case mémoire pointe par BX+2
Remarque :
Les syntaxes suivantes sont identiques :
MOV AX,[BX+2] MOV AX,[BX]+2MOV AX,2[BX]